Introduction
Artificial intelligence is entering a period where multiple foundational approaches are beginning to converge. For the past several years, the most visible advances in AI have come from Large Language Models (LLMs), systems capable of generating natural language, reasoning over text, and interacting conversationally with humans. However, a second class of models is rapidly gaining attention among researchers and practitioners: World Models.
World Models attempt to move beyond language by enabling machines to understand, simulate, and reason about the structure and dynamics of the real world. While LLMs excel at interpreting and generating symbolic information such as text and code, World Models focus on building internal representations of environments, physics, and causal relationships.
The distinction between these two paradigms is becoming increasingly important. Many researchers believe the next generation of intelligent systems will require both language-based reasoning and world-based simulation to operate effectively. Understanding how these models differ, where they overlap, and how they may eventually converge is becoming essential knowledge for anyone working in AI.
This article provides a structured examination of both approaches. It begins by defining each model type, then explores their technical architecture, capabilities, strengths, and limitations. Finally, it examines how these paradigms may shape the future trajectory of artificial intelligence.
The Foundations: What Are Large Language Models?
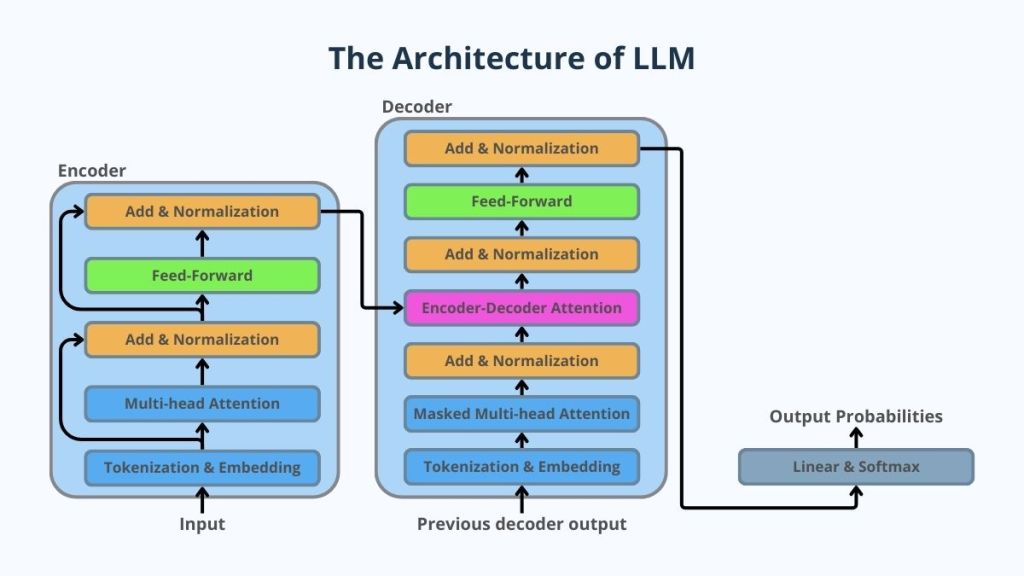
Large Language Models are deep neural networks trained on massive corpora of text data to predict the next token in a sequence. Although this objective may seem simple, the scale of data and model parameters allows these systems to develop rich representations of language, concepts, and relationships.
The majority of modern LLMs are built on the Transformer architecture, introduced in 2017. Transformers use a mechanism called self-attention, which allows the model to evaluate the relationships between all tokens in a sequence simultaneously rather than sequentially.
Through this mechanism, LLMs learn patterns across:
- natural language
- programming languages
- structured data
- documentation
- technical knowledge
- reasoning patterns
Examples of widely known LLMs include systems developed by major AI labs and technology companies. These models are used across applications such as:
- conversational AI
- coding assistants
- document analysis
- research tools
- decision support systems
- enterprise automation
LLMs do not explicitly understand the world in the human sense. Instead, they learn statistical patterns in language that reflect how humans describe the world.
Despite this limitation, the scale and structure of modern LLMs enable emergent capabilities such as:
- logical reasoning
- step-by-step planning
- code generation
- mathematical problem solving
- translation across languages and modalities
The Foundations: What Are World Models?
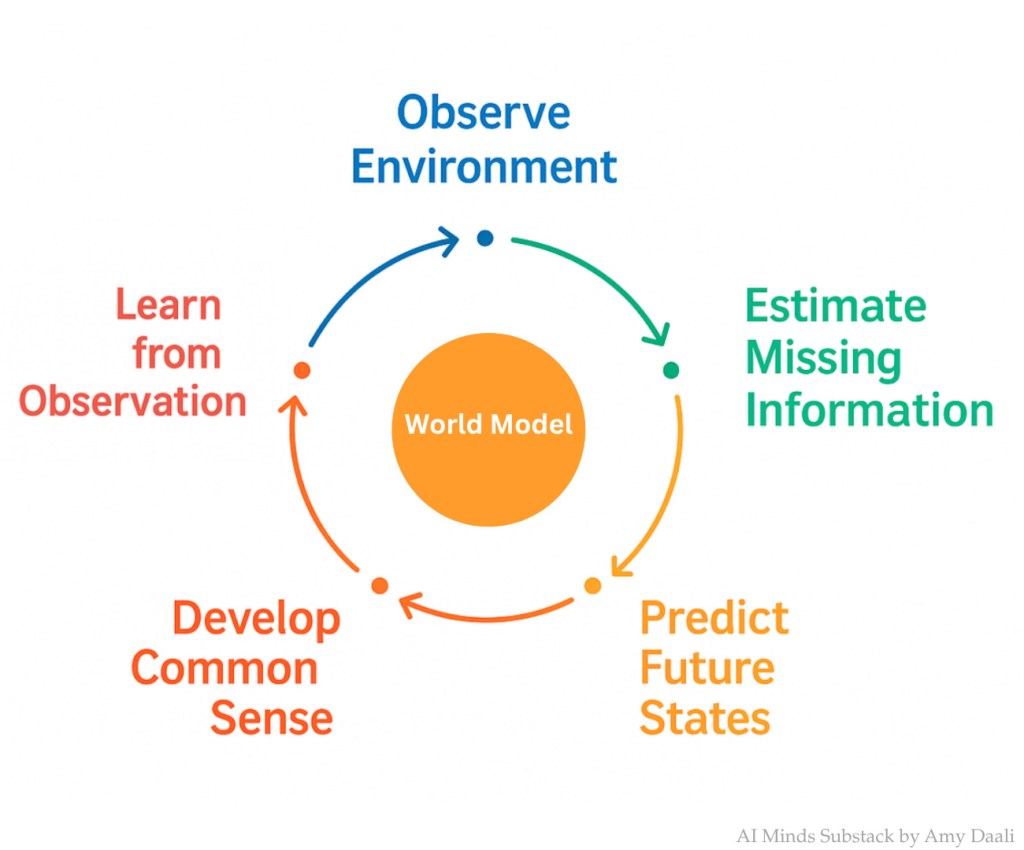
World Models represent a different philosophical approach to machine intelligence.
Rather than learning patterns from language, World Models attempt to build internal representations of environments and simulate how those environments evolve over time.
The concept was popularized in reinforcement learning research, where agents must interact with complex environments. A World Model allows an agent to predict future states of the world based on its actions, effectively enabling it to mentally simulate outcomes before acting.
In practical terms, a World Model learns:
- the structure of an environment
- causal relationships between objects
- how states change over time
- how actions influence outcomes
These models are frequently used in domains such as:
- robotics
- autonomous driving
- game environments
- physical simulation
- decision planning systems
Instead of predicting the next word in a sentence, a World Model predicts the next state of the environment.
This difference may appear subtle but it fundamentally changes how intelligence emerges within the system.
The Technical Architecture of Large Language Models
Modern LLMs typically consist of several core components that operate together to transform raw text into meaningful predictions.
Tokenization
Text must first be converted into tokens, which are numerical representations of words or sub-word units.
For example, a sentence might be converted into:
"The car accelerated quickly"
→
[Token 1243, Token 983, Token 4421, Token 903]
Tokenization allows the neural network to process language mathematically.
Embeddings
Each token is transformed into a high-dimensional vector representation.
These embeddings encode semantic meaning. Words with similar meaning tend to have similar vector representations.
For example:
- “car”
- “vehicle”
- “automobile”
would occupy nearby positions in vector space.
Transformer Layers
The Transformer is the core computational structure of LLMs.
Each layer contains:
- Self-Attention Mechanisms
- Feedforward Neural Networks
- Residual Connections
- Layer Normalization
Self-attention allows the model to determine which words in a sentence are relevant to one another.
For example, in the sentence:
“The dog chased the ball because it was moving.”
The model must determine whether “it” refers to the dog or the ball. Attention mechanisms help resolve this relationship.
Training Objective
LLMs are trained primarily using next-token prediction.
Given a sequence:
The stock market closed higher today because
The model predicts the most likely next token.
By repeating this process billions of times across enormous datasets, the model learns linguistic structure and conceptual relationships.
Fine-Tuning and Alignment
After pretraining, models are typically refined using techniques such as:
- Reinforcement Learning from Human Feedback
- Supervised Fine-Tuning
- Constitutional training approaches
These processes help align the model’s behavior with human expectations and safety guidelines.
The Technical Architecture of World Models
World Models use a different architecture because they must represent state transitions within an environment.
While implementations vary, many world models contain three fundamental components.
Representation Model
The first step is compressing sensory inputs into a latent representation.
For example, a robot might observe the environment using:
- camera images
- LiDAR data
- position sensors
These inputs are encoded into a latent vector that represents the current world state.
Common techniques include:
- Variational Autoencoders
- Convolutional Neural Networks
- latent state representations
Dynamics Model
The dynamics model predicts how the environment will evolve over time.
Given:
- current state
- action taken by the agent
the model predicts the next state.
Example:
State(t) + Action → State(t+1)
This allows an AI system to simulate future outcomes.
Policy or Planning Module
Finally, the system determines the best action to take.
Because the model can simulate outcomes, it can evaluate multiple possible futures and choose the most favorable one.
Techniques often used include:
- reinforcement learning
- Monte Carlo tree search
- planning algorithms
- policy optimization
Examples of World Models in Practice
World Models are already used in several advanced AI applications.
Robotics
Robots trained with world models can simulate how objects move before interacting with them.
Example:
A robotic arm may simulate the trajectory of a falling object before attempting to catch it.
Autonomous Vehicles
Self-driving systems rely heavily on predictive models that simulate the movement of other vehicles, pedestrians, and environmental changes.
A vehicle must anticipate:
- lane changes
- braking behavior
- pedestrian movement
These predictions form a real-time world model of the road.
Game AI
Game agents such as those used in complex strategy games simulate the future state of the game board to evaluate different strategies.
For example, an AI playing a strategy game might simulate thousands of possible moves before selecting an action.
Key Similarities Between LLMs and World Models
Despite their differences, these models share several foundational principles.
Both Learn Representations
Both models convert raw data into high-dimensional latent representations that capture relationships and patterns.
Both Use Deep Neural Networks
Modern implementations of both paradigms rely heavily on deep learning architectures.
Both Improve With Scale
Increasing:
- model size
- training data
- compute resources
improves performance in both approaches.
Both Support Planning and Reasoning
Although through different mechanisms, both systems can exhibit forms of reasoning.
LLMs reason through symbolic patterns in language, while World Models reason through environmental simulation.
Strengths and Weaknesses of Large Language Models
Large Language Models have become the most visible form of modern artificial intelligence due to their ability to interact through natural language and perform a wide range of cognitive tasks. Their strengths arise largely from the scale of training data, model architecture, and the statistical relationships they learn across language and code. At the same time, their weaknesses stem from the fact that they are fundamentally predictive language systems rather than grounded world-understanding systems.
Understanding both sides of this equation is essential when evaluating where LLMs provide significant value and where they require complementary technologies such as retrieval systems, reasoning frameworks, or world models.
Strengths of Large Language Models
1. Massive Knowledge Representation
One of the defining strengths of LLMs is their ability to encode vast amounts of knowledge within neural network weights. During training, these models ingest trillions of tokens drawn from sources such as:
- books
- research papers
- software repositories
- technical documentation
- websites
- structured datasets
Through exposure to this information, the model learns statistical relationships between concepts, enabling it to answer questions, summarize ideas, and explain complex topics.
Example
A well-trained LLM can simultaneously understand and explain concepts from multiple domains:
A user might ask:
“Explain the difference between Kubernetes container orchestration and serverless architecture.”
The model can produce a coherent explanation that references:
- distributed systems
- cloud infrastructure
- scalability models
- developer workflow implications
This ability to synthesize knowledge across domains is one of the most powerful characteristics of LLMs.
In enterprise settings, organizations frequently use LLMs to create knowledge assistants capable of navigating internal documentation, policy frameworks, and operational playbooks.
2. Natural Language Interaction
LLMs allow humans to interact with complex computational systems using everyday language rather than specialized programming syntax.
This capability dramatically lowers the barrier to accessing advanced technology.
Instead of writing complex database queries or scripts, a user can issue requests such as:
“Generate a financial summary of this quarterly report.”
or
“Write Python code that calculates customer churn using this dataset.”
Example
Customer support platforms increasingly integrate LLMs to assist service agents.
An agent might type:
“Summarize the issue and draft a response apologizing for the delay.”
The model can:
- analyze the customer’s conversation history
- summarize the root issue
- generate a professional response
This capability accelerates workflow efficiency and improves consistency in communication.
3. Multi-Task Generalization
Unlike traditional machine learning systems that are trained for a single task, LLMs can perform many tasks without retraining.
This capability is often described as zero-shot or few-shot learning.
A single model may handle tasks such as:
- translation
- coding assistance
- document summarization
- reasoning over data
- question answering
- brainstorming
- structured information extraction
Example
An enterprise knowledge assistant powered by an LLM might perform several different functions within a single workflow:
- Interpret a customer email
- Extract relevant product information
- Generate a response draft
- Translate the response into another language
- Log the interaction into a CRM system
This generalization capability is what makes LLMs highly adaptable across industries.
4. Code Generation and Technical Reasoning
One of the most impactful capabilities of LLMs is their ability to generate software code.
Because training datasets include large amounts of open-source code, models learn patterns across many programming languages.
These capabilities allow them to:
- generate code snippets
- explain algorithms
- debug software
- convert code between languages
- generate technical documentation
Example
A developer may prompt an LLM:
“Write a Python function that performs Monte Carlo simulation for stock price forecasting.”
The model can generate:
- the simulation logic
- comments explaining the method
- potential parameter adjustments
This capability has significantly accelerated development workflows and is one reason LLM-powered coding assistants are becoming standard developer tools.
5. Rapid Deployment Across Industries
LLMs can be integrated into a wide variety of applications with minimal changes to the core model.
Organizations frequently deploy them in areas such as:
- legal document review
- medical literature summarization
- financial analysis
- call center automation
- product recommendation systems
Example
In customer experience transformation programs, an LLM may be integrated into a contact center platform to assist agents by:
- summarizing customer history
- suggesting solutions
- generating follow-up communication
- automatically documenting case notes
This integration can reduce average handling time while improving customer satisfaction.
Weaknesses of Large Language Models
While LLMs demonstrate impressive capabilities, they also exhibit several limitations that practitioners must understand.
1. Lack of Grounded Understanding
LLMs learn relationships between words and concepts, but they do not interact directly with the physical world.
Their understanding of reality is therefore indirect and mediated through text descriptions.
This limitation means the model may understand how people talk about physical phenomena but may not fully capture the underlying physics.
Example
Consider a question such as:
“If I stack a bowling ball on top of a tennis ball and drop them together, what happens?”
A human with basic physics intuition understands that the tennis ball can rebound at high velocity due to energy transfer.
An LLM might produce inconsistent or incorrect explanations depending on how similar scenarios appeared in its training data.
World Models and physics-based simulations typically handle these scenarios more reliably because they explicitly model dynamics and physical laws.
2. Hallucinations
A widely discussed limitation of LLMs is hallucination, where the model produces information that appears plausible but is factually incorrect.
This occurs because the model’s objective is to generate the most statistically likely sequence of tokens, not necessarily the most accurate answer.
Example
If asked:
“Provide five peer-reviewed sources supporting a specific claim.”
The model may generate citations that appear legitimate but may not correspond to real publications.
This phenomenon has implications in domains such as:
- legal research
- academic writing
- financial analysis
- healthcare
To mitigate this issue, many enterprise deployments combine LLMs with retrieval systems (RAG architectures) that ground responses in verified data sources.
3. Limited Long-Term Reasoning and Planning
Although LLMs can demonstrate step-by-step reasoning in text form, they do not inherently simulate long-term decision processes.
They generate responses one token at a time, which can limit consistency across complex multi-step reasoning tasks.
Example
In strategic planning scenarios, an LLM may generate a reasonable short-term plan but struggle with maintaining coherence across a 20-step execution roadmap.
In contrast, systems that combine LLMs with planning algorithms or world models can simulate long-term outcomes more effectively.
4. Sensitivity to Prompting and Context
LLMs are highly sensitive to the phrasing of prompts and the context provided.
Small changes in wording can produce different outputs.
Example
Two similar prompts may produce significantly different answers:
Prompt A:
“Explain how blockchain improves financial transparency.”
Prompt B:
“Explain why blockchain may fail to improve financial transparency.”
The model may generate very different responses because it interprets each prompt as a framing signal.
While this flexibility can be useful, it also introduces unpredictability in production systems.
5. High Computational and Infrastructure Costs
Training large language models requires enormous computational resources.
Modern frontier models require:
- thousands of GPUs
- specialized data center infrastructure
- large energy consumption
- significant engineering effort
Even inference at scale can require substantial resources depending on the model size and response complexity.
Example
Enterprise deployments that serve millions of daily queries must carefully balance:
- latency
- cost per inference
- model size
- response quality
This is one reason smaller specialized models and fine-tuned domain models are becoming increasingly popular for targeted applications.
Key Takeaway
Large Language Models represent one of the most powerful and flexible AI technologies currently available. Their strengths lie in knowledge synthesis, language interaction, and task generalization, which allow them to operate effectively across a wide variety of domains.
However, their limitations highlight an important reality: LLMs are language prediction systems rather than complete models of intelligence.
They excel at interpreting and generating symbolic information but often require complementary systems to address areas such as:
- environmental simulation
- causal reasoning
- long-term planning
- real-world grounding
This recognition is one of the primary reasons researchers are increasingly exploring architectures that combine LLMs with world models, planning systems, and reinforcement learning agents. Together, these approaches may form the next generation of intelligent systems capable of both understanding language and reasoning about the structure of the real world.
Strengths and Weaknesses of World Models
World Models represent a different paradigm for artificial intelligence. Rather than learning patterns in language or static datasets, these systems learn how environments evolve over time. The central objective is to construct a latent representation of the world that can be used to predict future states based on actions.
This ability allows AI systems to simulate scenarios internally before acting in the real world. In many ways, World Models approximate a cognitive capability humans use regularly: mental simulation. Humans often predict the outcomes of actions before executing them. World Models attempt to replicate this capability computationally.
While still an active area of research, these systems are already playing a critical role in robotics, autonomous systems, reinforcement learning, and complex decision environments.
Strengths of World Models
1. Causal Understanding and Predictive Dynamics
One of the most significant strengths of World Models is their ability to capture cause-and-effect relationships.
Unlike LLMs, which rely on statistical correlations in text, World Models learn dynamic relationships between states and actions. They attempt to answer questions such as:
- If the agent performs action A, what state will occur next?
- How will the environment evolve over time?
- What sequence of actions leads to the optimal outcome?
This allows AI systems to reason about physical processes and environmental changes.
Example
Consider a robotic warehouse system tasked with moving packages efficiently.
A World Model allows the robot to simulate:
- how objects move when pushed
- how other robots will move through the space
- potential collisions
- the most efficient path to a destination
Before executing a movement, the robot can simulate multiple future trajectories and select the safest or most efficient one.
This predictive capability is essential for autonomous systems operating in real environments.
2. Internal Simulation and Planning
World Models allow agents to simulate future scenarios without interacting with the physical environment. This ability dramatically improves decision-making efficiency.
Instead of learning solely through trial and error in the real world, an agent can perform internal rollouts that test many possible strategies.
This is particularly useful in environments where experimentation is expensive or dangerous.
Example
Self-driving vehicles constantly simulate potential future events.
A vehicle approaching an intersection may simulate scenarios such as:
- another car suddenly braking
- a pedestrian entering the crosswalk
- a vehicle merging unexpectedly
The world model predicts how each scenario may unfold and helps determine the safest course of action.
This predictive modeling happens continuously and in real time.
3. Efficient Reinforcement Learning
Traditional reinforcement learning requires enormous numbers of interactions with an environment.
World Models can significantly reduce this requirement by allowing agents to learn within simulated environments generated by the model itself.
This technique is sometimes called model-based reinforcement learning.
Instead of learning purely from external interactions, the agent alternates between:
- real-world experience
- simulated experience generated by the world model
Example
Training a robotic arm to manipulate objects through physical trials alone may require millions of attempts.
By using a world model, the system can simulate thousands of possible grasping strategies internally before testing the most promising ones in the real environment.
This dramatically accelerates learning.
4. Multimodal Environmental Representation
World Models are particularly strong at integrating multiple types of sensory data.
Unlike LLMs, which are primarily trained on text, world models can incorporate signals from sources such as:
- images
- video
- spatial sensors
- depth cameras
- LiDAR
- motion sensors
These signals are encoded into a latent world representation that captures the structure of the environment.
Example
In robotics, a world model may integrate:
- visual input from cameras
- object detection data
- spatial mapping from LiDAR
- motion feedback from actuators
This combined representation enables the robot to understand:
- object positions
- physical obstacles
- motion trajectories
- spatial relationships
Such environmental awareness is critical for real-world interaction.
5. Strategic Planning and Long-Term Optimization
World Models excel at multi-step planning problems, where the consequences of actions unfold over time.
Because they simulate state transitions, they allow systems to evaluate long sequences of actions before choosing one.
Example
In logistics optimization, a world model might simulate different warehouse layouts to determine:
- robot travel time
- congestion patterns
- storage efficiency
- energy consumption
Instead of relying on static optimization models, the system can simulate dynamic interactions between many moving components.
This ability to evaluate future states makes world models extremely valuable in operational planning.
Weaknesses of World Models
Despite their potential, World Models also face several challenges that limit their current deployment.
1. Limited Generalization Across Domains
Most world models are trained for specific environments.
Unlike LLMs, which can generalize across many topics due to exposure to large text corpora, world models often specialize in narrow contexts.
For example, a model trained to simulate a robotic arm manipulating objects may not generalize well to:
- autonomous driving
- drone navigation
- household robotics
Each domain may require a new world model trained on domain-specific data.
Example
A warehouse robot trained in one facility may struggle when deployed in another facility with different layouts, lighting conditions, and object types.
This lack of generalization is a major research challenge.
2. Difficulty Modeling Complex Real-World Systems
The real world contains enormous complexity, including:
- unpredictable human behavior
- weather conditions
- sensor noise
- mechanical failure
- incomplete information
Building accurate models of these environments is extremely challenging.
Even small inaccuracies in the world model can accumulate over time and produce incorrect predictions.
Example
In autonomous driving systems, predicting the behavior of pedestrians is difficult because human behavior can be unpredictable.
If a world model incorrectly predicts pedestrian motion, it could lead to unsafe decisions.
This is why many safety-critical systems rely on hybrid architectures combining rule-based logic, statistical prediction models, and world modeling.
3. High Data Requirements
Training a reliable world model often requires large volumes of sensory data or simulated interactions.
Unlike language data, which is widely available online, real-world environment data must often be collected through sensors or physical experiments.
Example
Training a world model for a delivery robot might require:
- thousands of hours of video
- motion sensor recordings
- navigation logs
- object interaction data
Collecting and labeling this data can be expensive and time-consuming.
Simulation environments can help, but simulated environments may not perfectly match real-world physics.
4. Computational Complexity
Simulating environments and predicting future states can be computationally intensive.
High-fidelity world models may need to simulate:
- object physics
- environmental dynamics
- agent behavior
- stochastic events
Running these simulations at scale can require substantial computing resources.
Example
A robotic system that must simulate hundreds of possible action sequences before selecting a path may face latency challenges in real-time environments.
This creates engineering challenges when deploying world models in time-sensitive systems such as:
- autonomous vehicles
- industrial robotics
- air traffic management
5. Challenges in Representation Learning
Another technical challenge lies in learning accurate latent representations of the world.
The model must compress complex sensory information into a representation that captures the important aspects of the environment while ignoring irrelevant details.
If the representation fails to capture key features, the system’s predictions may degrade.
Example
A robotic manipulation system must recognize:
- object shape
- mass distribution
- friction
- contact surfaces
If the world model incorrectly encodes these properties, the robot may fail when attempting to grasp objects.
Learning representations that capture these physical properties remains an active area of research.
Key Takeaway
World Models represent a powerful approach for building AI systems that can reason about environments, predict outcomes, and plan actions.
Their strengths lie in:
- causal reasoning
- environmental simulation
- strategic planning
- multimodal perception
However, their limitations highlight why they remain an evolving area of research.
Challenges such as:
- environment complexity
- domain specialization
- high data requirements
- computational costs
must be addressed before world models can achieve broad general intelligence.
For many researchers, the most promising future architecture will combine LLMs for abstract reasoning and language understanding with World Models for environmental simulation and decision planning. Systems that integrate these capabilities may be able to both interpret complex instructions and simulate the real-world consequences of actions, which is a key step toward more advanced artificial intelligence.
The Future: Convergence of Language and World Understanding
Many researchers believe that the next wave of AI innovation will combine both paradigms.
An integrated system might include:
- LLMs for reasoning and communication
- World Models for simulation and planning
- Reinforcement learning for action selection
Such systems could reason about complex problems while simultaneously simulating potential outcomes.
For example:
A future autonomous system could receive a natural language instruction such as:
“Design the most efficient warehouse layout.”
The LLM component could interpret the request and generate candidate strategies.
The World Model could simulate:
- robot traffic patterns
- storage optimization
- worker safety
The combined system could then iteratively refine the design.
A Long-Term Vision for Artificial Intelligence
Looking ahead, the distinction between LLMs and World Models may gradually diminish.
Future architectures may incorporate:
- multimodal perception
- environment simulation
- language reasoning
- long-term memory
- planning systems
Some researchers argue that true artificial general intelligence will require an internal model of the world combined with symbolic reasoning capabilities.
Language alone may not be sufficient, and simulation alone may lack the abstraction needed for higher-order reasoning.
The most powerful systems may therefore be those that integrate both approaches into a unified architecture capable of understanding language, reasoning about complex systems, and predicting how the world evolves.
Final Thoughts
Large Language Models and World Models represent two distinct but complementary paths toward intelligent systems.
LLMs have demonstrated remarkable capabilities in language understanding, reasoning, and human interaction. Their rapid adoption across industries has transformed how humans interact with technology.
World Models, while less visible to the public, are advancing rapidly in research environments and are critical for enabling machines to understand and interact with the physical world.
The most important insight for practitioners is that these approaches are not competing paradigms. Instead, they represent different layers of intelligence.
Language models capture the structure of human knowledge and communication. World models capture the dynamics of environments and physical systems.
Together, they may form the foundation for the next generation of artificial intelligence systems capable of reasoning, planning, and interacting with the world in far more sophisticated ways than today’s technologies.
Follow us on (Spotify) as we discuss this and many other technology related topics.