
Human-Centered Problem Solving Meets Machine-Scale Intelligence

Introduction
Design Thinking and Artificial Intelligence are often positioned in separate domains, one grounded in human empathy and creative exploration, the other in data-driven modeling and computational scale. Yet in practice, both disciplines aim to solve complex problems under uncertainty. Design Thinking provides the structured yet flexible framework for understanding human needs, reframing ambiguous challenges, and iterating toward viable solutions. Artificial Intelligence contributes the ability to process vast datasets, identify hidden correlations, simulate outcomes, and quantify trade-offs. The correlation between the two emerges from their shared objective: reducing uncertainty while increasing confidence in decision making. Where Design Thinking surfaces qualitative insight, AI can validate, expand, and stress-test those insights through quantitative rigor.
Blending these methodologies creates a powerful lens for management consulting engagements, particularly when conducting solution design, SWOT analysis, and Root Cause Analysis. Design Thinking ensures that strategic options are grounded in stakeholder reality and organizational context, while AI introduces evidence-based pattern recognition and scenario modeling that strengthens the robustness of recommendations. Together they enable consultants to explore alternatives more comprehensively, challenge assumptions with data, and uncover systemic drivers that may otherwise remain obscured. The result is not simply faster analysis, but deeper insight, allowing leadership teams to move forward with solutions that are both human-centered and analytically resilient.
Let’s start with a general understanding of what Design Thinking is;
Part I. Design Thinking: Origins, Foundations, and Evolution in Consulting
Historical Roots
Design Thinking did not originate in the digital era. Its intellectual roots trace back to the 1960s and 1970s within the academic design sciences, most notably through the work of Herbert A. Simon, whose book The Sciences of the Artificial introduced the idea that design is a structured method of problem solving rather than purely artistic expression. Simon framed design as the process of transforming existing conditions into preferred ones, establishing the philosophical foundation that still underpins Design Thinking today.
The methodology gained institutional structure at Stanford University’s d.school and through the innovation firm IDEO in the 1990s and early 2000s. IDEO operationalized design as a repeatable process usable beyond product design, expanding into services, systems, and business model innovation. Over time, Design Thinking evolved from a designer’s craft into a strategic problem-solving framework used across industries including healthcare, finance, technology, and public sector transformation.
Core Fundamentals
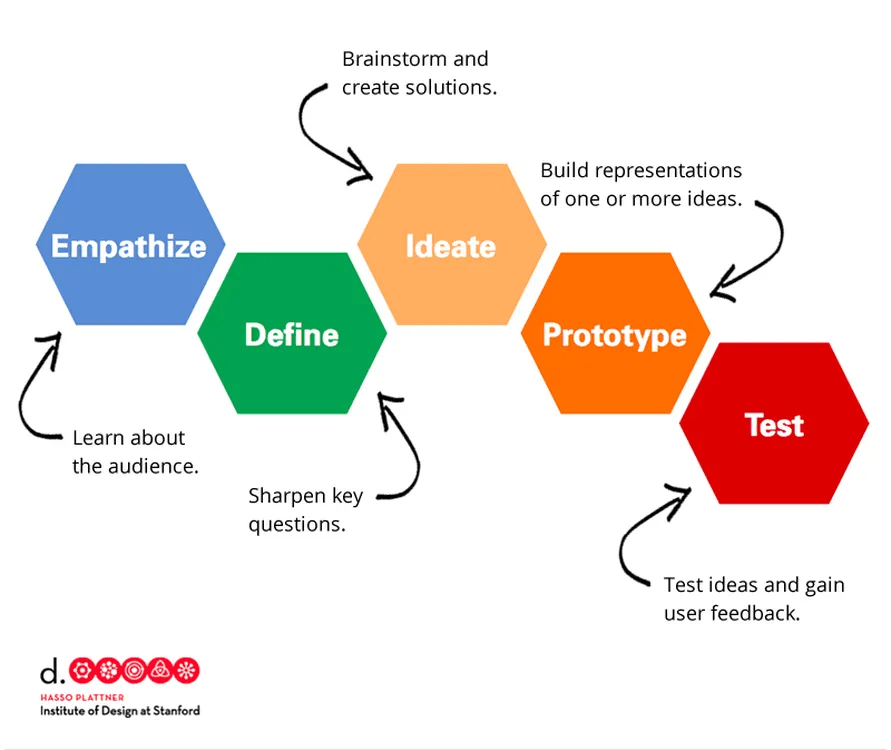
At its foundation, Design Thinking is human-centered, iterative, and exploratory rather than linear. While variations exist, most frameworks follow five stages:
- Empathize
Deeply understand user needs, behaviors, motivations, and constraints through observation and engagement. - Define
Frame the problem clearly based on insights rather than assumptions. - Ideate
Generate a broad set of potential solutions without premature filtering. - Prototype
Create rapid, low-cost representations of ideas. - Test
Validate solutions with users, refine continuously, and iterate.
The power of Design Thinking lies in reframing ambiguity into solvable constructs while maintaining a strong connection to human outcomes.
Role in Management Consulting
Management consulting firms adopted Design Thinking as digital transformation and customer experience became strategic priorities. Firms integrated it into:
- Customer journey redesign
- Product and service innovation
- Enterprise transformation
- Experience-led operating models
- Change management initiatives
Design Thinking became particularly valuable when organizations faced unclear problems rather than optimization challenges. Consulting teams used workshops, journey mapping, ethnographic research, and co-creation sessions to uncover latent needs and design solutions grounded in human behavior rather than purely operational metrics.
Over time, firms blended Design Thinking with Agile delivery, Lean experimentation, and data-driven decision making, positioning it as a front-end innovation engine for transformation programs.
Part II. The Intersection of Artificial Intelligence and Design Thinking
From Human Insight to Intelligent Systems
The intersection of Design Thinking and Artificial Intelligence is not simply about inserting technology into workshops. It represents the convergence of two complementary problem-solving paradigms: one rooted in human-centered exploration, the other in computational intelligence and predictive modeling. Design Thinking helps organizations understand what problem should be solved and why it matters. AI helps determine how the problem behaves at scale and what outcomes are most likely. Together they create a closed-loop system of discovery, insight, and adaptive execution.
To understand this intersection more clearly, it is useful to examine how both approaches operate across four dimensions: problem framing, insight generation, solution exploration, and adaptive learning.
1. Problem Framing: From Ambiguity to Structured Understanding
Design Thinking begins with ambiguity. Many strategic challenges faced by organizations are not clearly defined optimization problems but complex, multi-variable systems with human, operational, and environmental dependencies. Through empathy, observation, and reframing, Design Thinking transforms loosely understood challenges into structured problem statements grounded in real user and stakeholder needs.
Artificial Intelligence strengthens this phase by introducing data-backed problem validation. Instead of relying solely on qualitative observations, AI can analyze historical performance, behavioral data, and systemic relationships to reveal whether the perceived problem aligns with measurable reality.
Example
A financial services organization believes declining customer satisfaction is caused by poor digital experience. Design Thinking workshops uncover emotional frustration in customer journeys. AI analysis of interaction data reveals the largest driver is actually delayed issue resolution rather than interface usability. Together, they refine the problem definition from “improve digital UX” to “reduce resolution latency across channels.”
Intersection Value
- Design Thinking ensures the problem remains human-relevant
- AI ensures the problem is systemically accurate
- The combined approach reduces misdirected transformation efforts
2. Insight Generation: Expanding Beyond Human Observation
Design Thinking relies heavily on ethnographic research, interviews, and observational methods to uncover latent needs. These methods are powerful but limited in scale and sometimes influenced by sampling bias or subjective interpretation.
AI introduces pattern recognition at scale. Machine learning models can identify correlations across millions of data points, revealing behavioral clusters, emotional drivers, and systemic inefficiencies not easily visible through manual analysis.
Example
In a retail transformation initiative, Design Thinking identifies that customers value personalization. AI clustering of purchase behavior reveals multiple distinct personalization archetypes rather than a single unified preference pattern. This insight allows segmentation-driven experience design instead of one-size-fits-all personalization.
Intersection Value
- Design Thinking reveals meaning and context
- AI reveals scale and hidden patterns
- Together they deepen understanding rather than replacing human interpretation
3. Solution Exploration: Expanding the Design Space
The ideation phase in Design Thinking encourages divergent thinking and creativity. However, human ideation can be constrained by cognitive bias, prior experience, and limited scenario exploration.
Generative AI expands the solution design space by introducing alternative concepts, cross-industry analogies, and scenario-based variations that might not naturally emerge in workshop environments. AI can also simulate downstream implications of proposed ideas, providing early-stage foresight into feasibility and impact.
Example
A telecommunications firm redesigning its customer onboarding journey generates several human-designed concepts through workshops. AI simulation models test each concept against projected adoption, operational cost, and churn reduction. The combined approach identifies a hybrid model that balances experience quality with operational efficiency.
Intersection Value
- Design Thinking promotes creativity and desirability
- AI introduces feasibility and predictive foresight
- The combination reduces solution blind spots
4. Adaptive Learning: From Iteration to Continuous Intelligence
Design Thinking is inherently iterative. Prototypes are tested, feedback is gathered, and solutions evolve over time. However, traditional iteration cycles can be slow and dependent on periodic feedback loops.
AI enables continuous adaptive learning, allowing solutions to evolve dynamically based on real-time data. Instead of periodic redesign, organizations can move toward continuously learning systems that adapt to changing conditions.
Example
In a healthcare service redesign, Design Thinking shapes the patient-centered care model. AI monitors treatment outcomes, patient engagement, and system efficiency in real time, continuously optimizing scheduling, intervention timing, and care pathways.
Intersection Value
- Design Thinking ensures solutions remain human-centered
- AI enables real-time evolution and adaptation
- Together they create living systems rather than static solutions
Deeper Structural Alignment Between the Two Approaches
Beyond workshop phases, the intersection also exists at a structural level:
| Design Thinking Capability | AI Capability | Combined Impact |
|---|---|---|
| Empathy and human meaning | Behavioral and sentiment analysis | Emotionally intelligent and data-backed solutions |
| Creative ideation | Generative modeling | Expanded innovation space |
| Iterative prototyping | Simulation and prediction | Faster and more informed iteration |
| Human judgment | Pattern recognition | Balanced decision intelligence |
| Qualitative insight | Quantitative validation | Stronger strategic confidence |
Practical Implications for Consulting and Transformation
When applied in consulting environments, this intersection changes how complex problems are approached:
- Workshops become evidence-informed rather than purely exploratory
- Solution design becomes predictive rather than reactive
- Root Cause Analysis becomes systemic rather than surface-level
- SWOT analysis becomes data-augmented rather than perception-driven
- Transformation becomes adaptive rather than static
The outcome is not simply improved efficiency but a deeper capacity to address complex adaptive problems where human behavior, operational systems, and environmental dynamics intersect.
A Closing Perspective on the Intersection
The relationship between Design Thinking and Artificial Intelligence is not about replacing human-centered innovation with machine intelligence. Instead, it is about creating a layered problem-solving architecture where human insight guides direction and artificial intelligence enhances clarity, scale, and adaptability.
Design Thinking ensures organizations solve meaningful problems.
AI ensures those solutions can evolve, scale, and sustain impact.
Understanding this intersection equips leaders and practitioners to move beyond isolated methodologies and toward integrated intelligence capable of addressing the complexity of modern organizational and societal challenges.
Part III. Where AI Fits Inside the Design Thinking Process
1. Empathize Phase: Augmenting Human Insight
How AI contributes
AI can analyze large behavioral datasets, sentiment patterns, and customer interactions to reveal needs not immediately visible through qualitative observation.
Examples
- NLP models analyzing thousands of customer service transcripts
- Behavioral clustering from product usage data
- Emotion detection from feedback channels
Value
AI broadens insight scale while Design Thinking preserves human interpretation and contextual understanding.
2. Define Phase: Precision in Problem Framing
How AI contributes
AI helps synthesize unstructured information into structured themes and identifies root cause correlations across complex systems.
Examples
- Topic modeling from interviews and research notes
- Predictive drivers of churn or dissatisfaction
- Systemic bottleneck identification
Value
AI enhances clarity, but human facilitators ensure that problems remain grounded in human outcomes rather than purely statistical signals.
3. Ideate Phase: Expanding Solution Space
How AI contributes
Generative AI expands ideation beyond human cognitive limits by producing alternative scenarios, cross-industry analogies, and novel combinations.
Examples
- Generating multiple service design models
- Scenario simulation of future operating environments
- Concept recombination across domains
Value
AI increases breadth of ideation, while human judgment filters feasibility, ethics, and desirability.
4. Prototype Phase: Accelerating Creation
How AI contributes
AI can rapidly generate interface mockups, workflow models, system architectures, and digital twins.
Examples
- Generative UI wireframes
- Automated journey simulations
- Predictive system prototypes
Value
Prototyping becomes faster and less resource intensive, allowing more iterations within shorter cycles.
5. Test Phase: Continuous Learning at Scale
How AI contributes
AI enables real-time experimentation, simulation, and outcome prediction before full deployment.
Examples
- A/B testing at scale
- Predictive adoption modeling
- Behavioral response simulation
Value
AI strengthens evidence-based iteration while Design Thinking ensures solutions remain aligned to human value.
Part IV. Why Artificial Intelligence and Design Thinking Complement Each Other
Balancing Human Meaning with Computational Intelligence
At a structural level, Design Thinking and Artificial Intelligence address different dimensions of complexity. Design Thinking excels in navigating ambiguity, human behavior, and contextual nuance. AI excels in navigating scale, variability, and probabilistic uncertainty. When used independently, each approach has inherent blind spots. When combined deliberately, they create a more complete decision architecture.
To understand why they complement each other, it is useful to examine the specific limitations of each discipline and how the other compensates.
1. Design Thinking Addresses Critical Limitations in AI
AI systems are only as strong as the problem definitions, data inputs, and objective functions they are given. Without careful framing, AI can optimize the wrong outcome or reinforce unintended bias.
A. Human Context and Meaning
AI can detect patterns in behavior, but it does not inherently understand why those patterns matter emotionally, ethically, or culturally.
Example
A machine learning model identifies that reducing average call handling time improves cost efficiency. However, Design Thinking interviews reveal that customers value reassurance and clarity during complex service interactions. If the AI objective focuses solely on speed, the organization risks degrading trust.
Design Thinking ensures:
- The optimization target aligns with human value
- Emotional and experiential dimensions are preserved
- Success metrics reflect more than operational efficiency
B. Ethical Framing and Bias Mitigation
AI systems can perpetuate systemic bias if trained on skewed datasets or designed without inclusive perspectives.
Design Thinking workshops, particularly when diverse stakeholders are included, help surface:
- Edge cases
- Underrepresented user groups
- Potential unintended consequences
Example
In designing a digital lending platform, AI may identify demographic patterns that correlate with repayment likelihood. Design Thinking exploration can question whether those correlations reflect structural inequities rather than true creditworthiness, prompting governance safeguards.
C. Problem Selection and Relevance
AI is often deployed as a solution in search of a problem. Design Thinking ensures that the organization is solving the right issue.
Example
An enterprise may seek to implement predictive AI for supply chain optimization. Design Thinking may uncover that the real constraint lies in change management and supplier collaboration rather than predictive accuracy. The AI solution then becomes part of a broader transformation rather than a standalone tool.
2. AI Addresses Structural Constraints in Design Thinking
While Design Thinking is powerful for human-centered exploration, it has practical limits when dealing with large-scale systems and high-velocity environments.
A. Scale and Pattern Recognition
Human research methods are intensive but small in scale. AI can process millions of interactions to detect:
- Emerging behavioral shifts
- Correlated drivers of dissatisfaction
- Hidden operational bottlenecks
Example
During a customer experience redesign, workshops identify five major pain points. AI analysis of transactional and behavioral data uncovers three additional drivers not mentioned in interviews but statistically significant in churn prediction.
This does not invalidate Design Thinking. It enhances it by expanding insight coverage.
B. Predictive Foresight
Design Thinking prototypes are often tested through qualitative validation. AI introduces scenario modeling and predictive simulation.
Example
When redesigning a pricing model, Design Thinking may generate several concepts based on perceived fairness and value. AI can simulate revenue impact, adoption elasticity, and margin compression under different economic scenarios.
The combination produces solutions that are:
- Desirable
- Feasible
- Economically viable
- Future resilient
C. Continuous Adaptation
Traditional Design Thinking culminates in implementation and periodic iteration. AI enables real-time adaptation.
Example
A redesigned digital onboarding experience may initially test well in workshops. AI monitoring of engagement data post-launch can identify micro-frictions in real time, automatically adjusting messaging, sequencing, or support interventions.
This creates a feedback loop where the system continues to evolve rather than remaining static until the next redesign initiative.
The Complementary Architecture: Human Intelligence and Machine Intelligence
When integrated intentionally, the two approaches form a multi-layered intelligence stack:
- Human Framing Layer
Defines purpose, values, and meaningful outcomes - Data Intelligence Layer
Identifies patterns, correlations, and probabilistic drivers - Creative Expansion Layer
Explores broad solution possibilities through human ideation and generative modeling - Simulation and Validation Layer
Tests viability, risk, and scalability using predictive analytics - Adaptive Learning Layer
Continuously refines solutions through ongoing data feedback
Neither discipline can fully operate all layers independently. Design Thinking dominates the first layer. AI dominates the fourth and fifth. The middle layers benefit from hybrid collaboration.
Complementarity in SWOT and Root Cause Analysis
The integration becomes particularly evident in structured analytical frameworks.
SWOT Analysis
- Design Thinking captures stakeholder perception of strengths and weaknesses.
- AI validates and quantifies those factors through performance data and competitive benchmarking.
Example
Leadership perceives brand loyalty as a key strength. AI sentiment analysis reveals emerging dissatisfaction in specific segments. The SWOT becomes more nuanced and less perception-driven.
Root Cause Analysis
Traditional root cause workshops often rely on facilitated discussion and experience-based reasoning. AI can map causal relationships across operational datasets to identify non-obvious drivers.
Example
A manufacturing firm attributes delivery delays to warehouse inefficiency. AI process mining reveals that upstream supplier variability is the primary systemic constraint. Design Thinking then reframes the operational intervention.
Managing Cognitive Bias
Design Thinking can be influenced by facilitator bias, dominant voices in workshops, and anecdotal reasoning. AI can provide objective counterpoints through empirical data.
Conversely, AI can reinforce historical bias. Design Thinking can challenge assumptions by introducing alternative perspectives and qualitative nuance.
Together they create a system of checks and balances.
Strategic Implications for Leadership
For executives and consultants, the complementarity suggests several operating principles:
- Do not initiate AI projects without human-centered framing.
- Do not rely solely on workshop insight without data validation.
- Use AI to expand option sets, not prematurely constrain them.
- Preserve human judgment in defining success criteria.
- Embed continuous learning loops post-implementation.
Organizations that treat AI as an enhancement to human-centered design rather than a replacement are more likely to create resilient and adaptive solutions.
A Complementary Final Reflection
Design Thinking and Artificial Intelligence operate at different ends of the intelligence spectrum. One navigates empathy, meaning, and ambiguity. The other navigates scale, probability, and complexity. Their complementarity lies in their asymmetry.
Design Thinking ensures that organizations pursue the right direction.
AI ensures they navigate that direction efficiently and adaptively.
When both are applied deliberately, solution design becomes not only innovative but structurally sound, analytically rigorous, and continuously improving.
Part V. Applying Both to Complex Problem Spaces
Below are scenarios where the integration of both approaches becomes particularly powerful.
Scenario 1. Healthcare System Redesign
Challenge
Fragmented patient journeys, rising costs, and inconsistent care quality.
Design Thinking Contribution
- Deep patient empathy mapping
- Care journey redesign
- Stakeholder co-creation
AI Contribution
- Predictive diagnosis models
- Resource allocation optimization
- Patient outcome forecasting
Combined Outcome
A human-centered yet data-intelligent care model improving both experience and system efficiency.
Scenario 2. Enterprise Customer Experience Transformation
Challenge
Disconnected channels, inconsistent personalization, declining loyalty.
Design Thinking Contribution
- Journey mapping
- Emotion-driven experience design
- Service blueprinting
AI Contribution
- Real-time personalization engines
- Sentiment prediction
- Behavioral modeling
Combined Outcome
Adaptive, continuously learning customer experiences grounded in emotional relevance and operational intelligence.
Scenario 3. Smart Cities and Urban Systems
Challenge
Infrastructure strain, sustainability pressures, population growth.
Design Thinking Contribution
- Citizen-centered urban design
- Mobility and accessibility framing
- Social and behavioral insight
AI Contribution
- Traffic optimization
- Energy consumption prediction
- Environmental simulation
Combined Outcome
Cities designed around human life quality while optimized through predictive system intelligence.
Scenario 4. Complex Organizational Transformation
Challenge
Cultural resistance, unclear strategy, fragmented execution.
Design Thinking Contribution
- Human adoption mapping
- Change journey design
- Leadership alignment
AI Contribution
- Organizational network analysis
- Transformation risk modeling
- Scenario planning
Combined Outcome
Transformation programs that are both human-adoptable and analytically resilient.
Final Perspective
Design Thinking and Artificial Intelligence operate at different but complementary layers of problem solving. One prioritizes human meaning, the other computational intelligence. When integrated deliberately, they form a system capable of addressing ambiguity, complexity, and scale simultaneously.
Neither replaces the other. Design Thinking ensures problems are worth solving. AI ensures solutions can scale and adapt.
Organizations that learn to orchestrate both disciplines may find themselves better equipped to solve increasingly complex human and systemic challenges, not by choosing between human insight and machine intelligence, but by allowing each to enhance the other in a continuous cycle of discovery, design, and evolution.
Please follow us on (Spotify) as we cover this and many other topics.












