In the digital age, Artificial Intelligence (AI) has transcended its initial boundaries, weaving its transformative threads into the very fabric of our daily lives and various sectors, from healthcare and finance to entertainment and travel. Our past blog posts have delved deep into the concepts and technologies underpinning AI, unraveling its capabilities, challenges, and impacts across industries and personal experiences. As we’ve explored the breadth of AI’s applications, from automating mundane tasks to driving groundbreaking innovations, it’s clear that this technology is not just a futuristic notion but a present-day tool reshaping our world.
Now, as Spring Break approaches, the opportunity to marry AI’s prowess with the joy of vacation planning presents itself, offering a new frontier in our exploration of AI’s practical benefits. The focus shifts from theoretical discussions to real-world application, demonstrating how AI can elevate a traditional Spring Break getaway into an extraordinary, hassle-free adventure.
Imagine leveraging AI to craft a Spring Break experience that not only aligns with your interests and preferences but also adapts dynamically to ensure every moment is optimized for enjoyment and discovery. Whether it’s uncovering hidden gems in Tucson, Mesa, or the vast expanses of the Tonto National Forest, AI’s predictive analytics, personalized recommendations, and real-time insights can transform the way we experience travel. This blog post aims to bridge the gap between AI’s theoretical potential and its tangible benefits, illustrating how it can be a pivotal ally in creating a Spring Break vacation that stands out not just for its destination but for its innovation and seamless personalization, ensuring a memorable journey for a father and his 19-year-old son.
But how can they ensure their trip is both thrilling and smooth? This is where Artificial Intelligence (AI) steps in, transforming vacation planning and experiences from the traditional hit-and-miss approach to a streamlined, personalized journey. We will dive into how AI can be leveraged to discover exciting activities and hikes, thereby enhancing the father-son bonding experience while minimizing the uncertainties typically associated with vacation planning.
Discovering Arizona with AI:
AI-Powered Travel Assistants:
Personalized Itinerary Creation: AI-driven travel apps can analyze your preferences, past trip reviews, and real-time data to suggest activities and hikes in Tucson, Mesa, and the Tonto National Forest tailored to your interests.
Dynamic Adjustment: These platforms can adapt your itinerary based on real-time weather updates, unexpected closures, or even your real-time feedback, ensuring your plans remain optimal and flexible.
AI-Enhanced Discovery:
Virtual Exploration: Before setting foot in Arizona, virtual tours powered by AI can offer a sneak peek into various attractions, providing a better sense of what to expect and helping you prioritize your visit list.
Language Processing: AI-powered chatbots can understand and respond to your queries in natural language, offering instant recommendations and insights about local sights, thus acting as a 24/7 digital concierge.
Optimized Route Planning:
Efficient Navigation: AI algorithms can devise the most scenic or fastest routes for your hikes and travels between cities, considering current traffic conditions, road work, and even scenic viewpoints.
Location-based Suggestions: While exploring, AI can recommend nearby points of interest, eateries, or even less crowded trails, enhancing your exploration experience.
Surprise Divergence: Even AI can’t always predict the off route suggestion to Fountain Hills, Arizona where the world famous Fountain (as defined by EarthCam) is located.
AI vs. Traditional Planning:
Efficiency: AI streamlines the research and planning process, reducing hours of browsing through various websites to mere minutes of automated, personalized suggestions.
Personalization: Unlike one-size-fits-all travel guides, AI offers tailored advice that aligns with your specific interests and preferences, whether you’re seeking adrenaline-fueled adventures or serene nature walks.
Informed Decision-Making: AI’s ability to analyze vast datasets allows for more informed recommendations, based on reviews, ratings, and even social media trends, ensuring you’re aware of the latest and most popular attractions.
Creating Memories with AI:
AI-Enhanced Photography:
Utilize AI-powered photography apps to capture stunning images of your adventures, with features like optimal lighting adjustments and composition suggestions to immortalize your trip’s best moments.
Travel Journals and Blogs:
AI can assist in creating digital travel journals or blogs, where you can combine your photos and narratives into a cohesive story, offering a modern twist to the classic travelogue.
Cultural Engagement:
Language translation apps and cultural insight tools can deepen your understanding and appreciation of the places you visit, fostering a more immersive and enriching experience.
Conclusion:
Embracing AI in your Spring Break trip planning and execution can significantly enhance your father-son adventure, making it not just a vacation but an experience brimming with discovery, ease, and personalization. From uncovering hidden gems in the Tonto National Forest to capturing and sharing breathtaking moments, AI becomes your trusted partner in crafting a journey that’s as unique as it is memorable. As we step into this new era of travel, let AI take the wheel, guiding you to a more connected, informed, and unforgettable exploration of Arizona’s beauty.
As we approach the 2024 United States elections, the rapid advancements in Artificial Intelligence (AI) and the potential development of Artificial General Intelligence (AGI) have become increasingly relevant topics of discussion. The incorporation of cutting-edge AI and AGI technologies, particularly multimodal models, by leading AI firms such as OpenAI, Anthropic, Google, and IBM, has the potential to significantly influence various aspects of the election process. In this blog post, we will explore the importance of these advancements and their potential impact on the 2024 elections.
Understanding AGI and Multimodal Models
Before delving into the specifics of how AGI and multimodal models may impact the 2024 elections, it is essential to define these terms. AGI refers to the hypothetical ability of an AI system to understand or learn any intellectual task that a human being can. While current AI systems excel at specific tasks, AGI would have a more general, human-like intelligence capable of adapting to various domains.
Multimodal models, on the other hand, are AI systems that can process and generate multiple forms of data, such as text, images, audio, and video. These models have the ability to understand and generate content across different modalities, enabling more natural and intuitive interactions between humans and AI.
The Role of Leading AI Firms
Companies like OpenAI, Anthropic, Google, and IBM have been at the forefront of AI research and development. Their latest product offerings, which incorporate multimodal models and advanced AI techniques, have the potential to revolutionize various aspects of the election process.
For instance, OpenAI’s GPT (Generative Pre-trained Transformer) series has demonstrated remarkable language understanding and generation capabilities. The latest iteration, GPT-4, is a multimodal model that can process both text and images, allowing for more sophisticated analysis and content creation.
Anthropic’s AI systems focus on safety and ethics, aiming to develop AI that is aligned with human values. Their work on constitutional AI and AI governance could play a crucial role in ensuring that AI is used responsibly and transparently in the context of elections.
Google’s extensive research in AI, particularly in the areas of natural language processing and computer vision, has led to the development of powerful multimodal models. These models can analyze vast amounts of data, including social media posts, news articles, and multimedia content, to provide insights into public sentiment and opinion.
IBM’s Watson AI platform has been applied to various domains, including healthcare and finance. In the context of elections, Watson’s capabilities could be leveraged to analyze complex data, detect patterns, and provide data-driven insights to campaign strategists and policymakers.
Potential Impact on the 2024 Elections
Sentiment Analysis and Voter Insights: Multimodal AI models can analyze vast amounts of data from social media, news articles, and other online sources to gauge public sentiment on various issues. By processing text, images, and videos, these models can provide a comprehensive understanding of voter opinions, concerns, and preferences. This information can be invaluable for political campaigns in crafting targeted messages and addressing the needs of specific demographics.
Personalized Campaign Strategies: AGI and multimodal models can enable political campaigns to develop highly personalized strategies based on individual voter profiles. By analyzing data on a voter’s interests, behavior, and engagement with political content, AI systems can suggest tailored campaign messages, policy positions, and outreach methods. This level of personalization can potentially increase voter engagement and turnout.
Misinformation Detection and Fact-Checking: The spread of misinformation and fake news has been a significant concern in recent elections. AGI and multimodal models can play a crucial role in detecting and combating the spread of false information. By analyzing the content and sources of information across various modalities, AI systems can identify patterns and inconsistencies that indicate potential misinformation. This can help fact-checkers and media organizations quickly verify claims and provide accurate information to the public.
Predictive Analytics and Forecasting: AI-powered predictive analytics can provide valuable insights into election outcomes and voter behavior. By analyzing historical data, polling information, and real-time social media sentiment, AGI systems can generate more accurate predictions and forecasts. This information can help campaigns allocate resources effectively, identify key battleground states, and adjust their strategies accordingly.
Policy Analysis and Decision Support: AGI and multimodal models can assist policymakers and candidates in analyzing complex policy issues and their potential impact on voters. By processing vast amounts of data from various sources, including academic research, government reports, and public opinion, AI systems can provide data-driven insights and recommendations. This can lead to more informed decision-making and the development of policies that better address the needs and concerns of the electorate.
Challenges and Considerations
While the potential benefits of AGI and multimodal models in the context of elections are significant, there are also challenges and considerations that need to be addressed:
Ethical Concerns: The use of AI in elections raises ethical concerns around privacy, transparency, and fairness. It is crucial to ensure that AI systems are developed and deployed responsibly, with appropriate safeguards in place to prevent misuse or manipulation.
Bias and Fairness: AI models can potentially perpetuate or amplify existing biases if not properly designed and trained. It is essential to ensure that AI systems used in the election process are unbiased and treat all voters and candidates fairly, regardless of their background or affiliations.
Transparency and Accountability: The use of AI in elections should be transparent, with clear guidelines on how the technology is being employed and for what purposes. There should be mechanisms in place to hold AI systems and their developers accountable for their actions and decisions.
Regulation and Governance: As AGI and multimodal models become more prevalent in the election process, there is a need for appropriate regulations and governance frameworks. Policymakers and stakeholders must collaborate to develop guidelines and standards that ensure the responsible and ethical use of AI in elections.
Conclusion
The advancements in AGI and multimodal models, driven by leading AI firms like OpenAI, Anthropic, Google, and IBM, have the potential to significantly impact the 2024 U.S. elections. From sentiment analysis and personalized campaign strategies to misinformation detection and predictive analytics, these technologies can revolutionize various aspects of the election process.
However, it is crucial to address the ethical concerns, biases, transparency, and governance issues associated with the use of AI in elections. By proactively addressing these challenges and ensuring responsible deployment, we can harness the power of AGI and multimodal models to enhance the democratic process and empower voters to make informed decisions.
As we move forward, it is essential for practitioners, policymakers, and the general public to stay informed about the latest advancements in AI and their potential impact on elections. By fostering a comprehensive understanding of these technologies and their implications, we can work towards a future where AI serves as a tool to strengthen democracy and promote the well-being of all citizens.
Last week we discussed advances in Gaussian Splatting and the impact on text-to-video content creation within the rapidly evolving landscape of artificial intelligence, these technologies are making significant strides and changing the way we think about content creation. Today we will discuss another technological advancement; Neural Radiance Fields (NeRF) and its impact on text-to-video AI. When these technologies converge, they unlock new possibilities for content creators, offering unprecedented levels of realism, customization, and efficiency. In this blog post, we will delve deep into these technologies, focusing particularly on their integration in OpenAI’s latest product, Sora, and explore their implications for the future of digital content creation.
Understanding Neural Radiance Fields (NeRF)
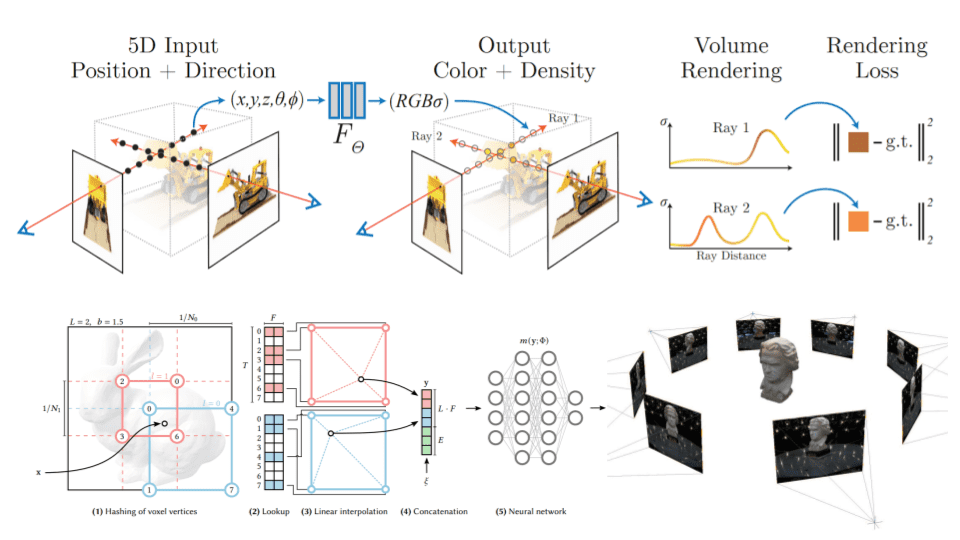
NeRF represents a groundbreaking approach to rendering 3D scenes from 2D images with astonishing detail and photorealism. This technology uses deep learning to interpolate light rays as they travel through space, capturing the color and intensity of light at every point in a scene to create a cohesive and highly detailed 3D representation. For content creators, NeRF offers a way to generate lifelike environments and objects from a relatively sparse set of images, reducing the need for extensive 3D modeling and manual texturing.
Expanded Understanding of Neural Radiance Fields (NeRF)
Neural Radiance Fields (NeRF) is a novel framework in the field of computer vision and graphics, enabling the synthesis of highly realistic images from any viewpoint using a sparse set of 2D input images. At its core, NeRF utilizes a fully connected deep neural network to model the volumetric scene functionally, capturing the intricate play of light and color in a 3D space. This section aims to demystify NeRF for technologists, illustrating its fundamental concepts and practical applications to anchor understanding.
Fundamentals of NeRF
NeRF represents a scene using a continuous 5D function, where each point in space (defined by its x, y, z coordinates) and each viewing direction (defined by angles θ and φ) is mapped to a color (RGB) and a volume density. This mapping is achieved through a neural network that takes these 5D coordinates as input and predicts the color and density at that point. Here’s how it breaks down:
Volume Density: This measure indicates the opaqueness of a point in space. High density suggests a solid object, while low density implies empty space or transparency.
Color Output: The predicted color at a point, given a specific viewing direction, accounts for how light interacts with objects in the environment.
When rendering an image, NeRF integrates these predictions along camera rays, a process that simulates how light travels and scatters in a real 3D environment, culminating in photorealistic image synthesis.
Training and Rendering
To train a NeRF model, you need a set of images of a scene from various angles, each with its corresponding camera position and orientation. The training process involves adjusting the neural network parameters until the rendered views match the training images as closely as possible. This iterative optimization enables NeRF to interpolate and reconstruct the scene with high fidelity.
During rendering, NeRF computes the color and density for numerous points along each ray emanating from the camera into the scene, aggregating this information to form the final image. This ray-marching process, although computationally intensive, results in images with impressive detail and realism.
Practical Examples and Applications
Virtual Tourism: Imagine exploring a detailed 3D model of the Colosseum in Rome, created from a set of tourist photos. NeRF can generate any viewpoint, allowing users to experience the site from angles never captured in the original photos.
Film and Visual Effects: In filmmaking, NeRF can help generate realistic backgrounds or virtual sets from a limited set of reference photos, significantly reducing the need for physical sets or extensive location shooting.
Cultural Heritage Preservation: By capturing detailed 3D models of historical sites or artifacts from photographs, NeRF aids in preserving and studying these treasures, making them accessible for virtual exploration.
Product Visualization: Companies can use NeRF to create realistic 3D models of their products from a series of photographs, enabling interactive customer experiences online, such as viewing the product from any angle or in different lighting conditions.
Key Concepts in Neural Radiance Fields (NeRF)
To understand Neural Radiance Fields (NeRF) thoroughly, it is essential to grasp its foundational concepts and appreciate how these principles translate into the generation of photorealistic 3D scenes. Below, we delve deeper into the key concepts of NeRF, providing examples to elucidate their practical significance.
Scene Representation
NeRF models a scene using a continuous, high-dimensional function that encodes the volumetric density and color information at every point in space, relative to the viewer’s perspective.
Example: Consider a NeRF model creating a 3D representation of a forest. For each point in space, whether on the surface of a tree trunk, within its canopy, or in the open air, the model assigns both a density (indicating whether the point contributes to the scene’s geometry) and a color (reflecting the appearance under particular lighting conditions). This detailed encoding allows for the realistic rendering of the forest from any viewpoint, capturing the nuances of light filtering through leaves or the texture of the bark on the trees.
Photorealism
NeRF’s ability to synthesize highly realistic images from any perspective is one of its most compelling attributes, driven by its precise modeling of light interactions within a scene.
Example: If a NeRF model is applied to replicate a glass sculpture, it would capture how light bends through the glass and the subtle color shifts resulting from its interaction with the material. The end result is a set of images so detailed and accurate that viewers might struggle to differentiate them from actual photographs of the sculpture.
Efficiency
Despite the high computational load required during the training phase, once a NeRF model is trained, it can render new views of a scene relatively quickly and with fewer resources compared to traditional 3D rendering techniques.
Example: After a NeRF model has been trained on a dataset of a car, it can generate new views of this car from angles not included in the original dataset, without the need to re-render the model entirely from scratch. This capability is particularly valuable for applications like virtual showrooms, where potential buyers can explore a vehicle from any angle or lighting condition, all generated with minimal delay.
Continuous View Synthesis
NeRF excels at creating smooth transitions between different viewpoints in a scene, providing a seamless viewing experience that traditional 3D models struggle to match.
Example: In a virtual house tour powered by NeRF, as the viewer moves from room to room, the transitions are smooth and realistic, with no abrupt changes in texture or lighting. This continuous view synthesis not only enhances the realism but also makes the virtual tour more engaging and immersive.
Handling of Complex Lighting and Materials
NeRF’s nuanced understanding of light and material interaction enables it to handle complex scenarios like transparency, reflections, and shadows with a high degree of realism.
Example: When rendering a scene with a pond, NeRF accurately models the reflections of surrounding trees and the sky in the water, the transparency of the water with varying depths, and the play of light and shadow on the pond’s bed, providing a remarkably lifelike representation.
The key concepts of NeRF—scene representation, photorealism, efficiency, continuous view synthesis, and advanced handling of lighting and materials—are what empower this technology to create stunningly realistic 3D environments from a set of 2D images. By understanding these concepts, technologists and content creators can better appreciate the potential applications and implications of NeRF, from virtual reality and filmmaking to architecture and beyond. As NeRF continues to evolve, its role in shaping the future of digital content and experiences is likely to expand, offering ever more immersive and engaging ways to interact with virtual worlds.
Advancements in Text-to-Video AI
Parallel to the developments in NeRF, text-to-video AI technologies are transforming the content landscape by enabling creators to generate video content directly from textual descriptions. This capability leverages advanced natural language processing and deep learning techniques to understand and visualize complex narratives, scenes, and actions described in text, translating them into engaging video content.
Integration with NeRF:
Dynamic Content Generation: Combining NeRF with text-to-video AI allows creators to generate realistic 3D environments that can be seamlessly integrated into video narratives, all driven by textual descriptions.
Customization and Flexibility: Content creators can use natural language to specify details about environments, characters, and actions, which NeRF and text-to-video AI can then bring to life with high fidelity.
OpenAI’s Sora: A Case Study in NeRF and Text-to-Video AI Convergence
OpenAI’s Sora exemplifies the integration of NeRF and text-to-video AI, illustrating the potential of these technologies to revolutionize content creation. Sora leverages NeRF to create detailed, realistic 3D environments from textual inputs, which are then animated and rendered into dynamic video content using text-to-video AI algorithms.
OpenAI Sora: SUV in The Dust
Implications for Content Creators:
Enhanced Realism: Sora enables the production of videos with lifelike environments and characters, raising the bar for visual quality and immersion.
Efficiency: By automating the creation of complex scenes and animations, Sora reduces the time and resources required to produce high-quality video content.
Accessibility: With Sora, content creators do not need deep technical expertise in 3D modeling or animation to create compelling videos, democratizing access to advanced content creation tools.
Conclusion
The integration of NeRF and text-to-video AI, as demonstrated by OpenAI’s Sora, marks a significant milestone in the evolution of content creation technology. It offers content creators unparalleled capabilities to produce realistic, engaging, and personalized video content efficiently and at scale.
As we look to the future, the continued advancement of these technologies will further expand the possibilities for creative expression and storytelling, enabling creators to bring even the most ambitious visions to life. For junior practitioners and seasoned professionals alike, understanding the potential and applications of NeRF and text-to-video AI is essential for staying at the forefront of the digital content creation revolution.
In conclusion, the convergence of NeRF and text-to-video AI is not just a technical achievement; it represents a new era in storytelling, where the barriers between imagination and reality are increasingly blurred. For content creators and consumers alike, this is a journey just beginning, promising a future rich with possibilities that are as limitless as our creativity.
In the rapidly evolving landscape of artificial intelligence, the introduction of text-to-video AI technologies marks a significant milestone. We highlighted the introduction and advancement of OpenAI’s product suite with their introduction of Sora (text-to-video) in our previous post. Embedded in these products, and typically without a lot of marketing fanfare are the technologies that continually drive this innovation and specifically one of them, Gaussian splatting, has emerged as a pivotal technique. This blog post delves into the intricacies of Gaussian splatting, its integration with current AI prompt technology, and its crucial role in enhancing content creation through text-to-video AI. Our aim is to provide a comprehensive understanding of this technology, making it accessible not only to seasoned professionals but also to junior practitioners eager to grasp the future of AI-driven content creation. Additionally, a companion technology is often discussed hand-in-hand with Gaussian splatting and that is called, Neural Radiance Fields (NeRF) and we will dive into that topic in a future post.
Understanding Gaussian Splatting
Gaussian splatting is a sophisticated technique used in the realm of computer graphics and image processing. It involves the use of Gaussian functions to simulate the effects of splatting or scattering light and particles. This method is particularly effective in creating realistic textures and effects in digital images by smoothly blending colors and intensities.
In the context of AI, Gaussian splatting plays a fundamental role in generating high-quality, realistic images and videos from textual descriptions. The technique allows for the seamless integration of various elements within a scene, ensuring that the generated visuals are not only convincing but also aesthetically pleasing.
Gaussian splatting, as a technique, is integral to many advanced computer graphics and image processing applications, particularly those involving the generation of realistic textures, lighting, and smooth transitions between visual elements. In the context of AI-driven platforms like OpenAI’s Sora, which is designed to generate video content from text prompts, Gaussian splatting and similar techniques are foundational to achieving high-quality, realistic outputs.
Is Gaussian Splatting Automatically Embedded?
In products like Sora, Gaussian splatting and other advanced image processing techniques are typically embedded within the AI models themselves. These models are trained on vast datasets that include examples of realistic textures, lighting effects, and color transitions, learning how to replicate these effects in generated content. This means that the application of Gaussian splatting is automatic and integrated into the content generation process, requiring no manual intervention from the user.
Understanding the Role of Gaussian Splatting in AI Products
For AI-driven content creation tools:
Automatic Application: Advanced techniques like Gaussian splatting are embedded within the AI’s algorithms, ensuring that the generated images, videos, or other visual content automatically include these effects for realism and visual appeal.
No Manual Requirement: Users do not need to apply Gaussian splatting or similar techniques manually. The focus is on inputting creative prompts, while the AI handles the complex task of rendering realistic outputs based on its training and built-in processing capabilities.
Enhanced Quality and Realism: The integration of such techniques is crucial for achieving the high quality and realism that users expect from AI-generated content. It enables the creation of visuals that are not just technically impressive but also emotionally resonant and engaging.
Expanding on Gaussian Splatting
Visually Understanding Gaussian Splatting
To deepen your understanding of Gaussian splatting, let’s examine an illustrative comparison. This illustration contrasts a scene with Gaussian splatting against one where Gaussian splatting is not applied. In the later, you’ll notice harsh transitions and unrealistic blending of elements, resulting in a scene that feels disjointed and artificial. Conversely, the scene employing Gaussian splatting showcases smooth color transitions and realistic effects, significantly enhancing the visual realism and aesthetic appeal.
Example: Enhancing Realism in Digital Imagery
Consider a sunset beach scene where people are walking along the shore. Without Gaussian splatting, the sunlight’s diffusion, shadows cast by the people, and the blending of the sky’s colors could appear abrupt and unnatural. The transitions between different elements of the scene might be too stark, detracting from the overall realism.
Now, apply Gaussian splatting to the same scene. This technique uses Gaussian functions to simulate the natural diffusion of light and the soft blending of colors. The result is a more lifelike representation of the sunset, with gently blended skies and realistically rendered shadows on the sand. The people walking on the beach are integrated into the scene seamlessly, with their outlines and the surrounding environment blending in a way that mimics the natural observation of such a scene.
This visual and example highlight the significance of Gaussian splatting in creating digital images and videos that are not just visually appealing but also convincingly realistic. By understanding and applying this technique, content creators can push the boundaries of digital realism, making artificial scenes indistinguishable from real-life observations.
The Advent of Text-to-Video AI
Text-to-video AI represents the next leap in content creation, enabling users to generate complex video content from simple text prompts. This technology leverages deep learning models to interpret textual descriptions and translate them into dynamic visual narratives. The process encompasses a wide range of tasks, including scene composition, object placement, motion planning, and the rendering of realistic textures and lighting effects.
Gaussian splatting becomes instrumental in this process, particularly in the rendering phase, where it ensures that the visual elements are blended naturally. It contributes to the realism and dynamism of the generated videos, making the technology invaluable for content creators seeking to produce high-quality visual content efficiently.
Integration with AI Prompt Technology
The integration of Gaussian splatting with AI prompt technology is a cornerstone of text-to-video AI systems. AI prompt technology refers to the mechanisms by which users can instruct AI models using natural language. These prompts are then interpreted by the AI to generate content that aligns with the user’s intent.
In the case of text-to-video AI, Gaussian splatting is employed to refine the visual output based on the textual prompts. For example, if a prompt describes a sunset scene with people walking on the beach, Gaussian splatting helps in creating the soft transitions of the sunset’s colors and the realistic blending of the people’s shadows on the sand. This ensures that the final video output closely matches the scene described in the prompt, with natural-looking effects and transitions.
OpenAI’s Sora: A Case Study in Innovation
OpenAI’s Sora stands as a testament to the potential of integrating Gaussian splatting with text-to-video AI. Sora is designed to offer content creators a powerful tool for generating high-quality video content directly from text descriptions. The platform utilizes advanced AI models, including those trained on Gaussian splatting techniques, to produce videos that are not only visually stunning but also deeply engaging.
The significance of Gaussian splatting in Sora’s technology stack cannot be overstated. It allows Sora to achieve a level of visual fidelity and realism that sets a new standard for AI-generated content. This makes Sora an invaluable asset for professionals in marketing, and digital content creation, who can leverage the platform to create compelling visual narratives with minimal effort.
Key Topics for Discussion and Understanding
To fully appreciate the impact of Gaussian splatting in text-to-video AI, several key topics warrant discussion:
Realism and Aesthetics: Understanding how Gaussian splatting contributes to the realism and aesthetic quality of AI-generated videos.
Efficiency in Content Creation: Exploring how this technology streamlines the content creation process, enabling faster production times without compromising on quality.
AI Prompt Technology: Delving into the advancements in AI prompt technology that make it possible to accurately translate text descriptions into complex visual content.
Applications and Implications: Considering the broad range of applications for text-to-video AI and the potential implications for industries such as marketing, entertainment, and education.
Conclusion
Gaussian splatting represents a critical technological advancement in the field of text-to-video AI, offering unprecedented opportunities for content creators. By understanding this technology and its integration with AI prompt technology, professionals can harness the power of platforms like OpenAI’s Sora to revolutionize the way visual content is created and consumed. As we look to the future, the potential of Gaussian splatting in enhancing digital transformation and customer experience through AI-driven content creation is immense, promising a new era of creativity and innovation in the digital landscape.
On Thursday 02/15/2024 we heard about the latest development from OpenAI – Sora (Text-to-Video AI). The introduction of OpenAI’s Sora into the public marketplace is set to revolutionize the content and media creation landscape over the next five years. This transformation will be driven by Sora’s advanced capabilities in generating, understanding, and processing natural language, as well as its potential for creative content generation. The impact on content creators, media professionals, and the broader ecosystem will be multifaceted, influencing production processes, content personalization, and the overall economics of the media industry.
Transformation of Content Creation Processes
Sora’s advanced AI capabilities can significantly streamline the content creation process, making it more efficient and cost-effective. For writers, journalists, and digital content creators, Sora can offer real-time suggestions, improve drafting efficiency, and provide editing assistance to enhance the quality of the output. This can lead to a reduction in the time and resources required to produce high-quality content, allowing creators to focus more on the creative and strategic aspects of their work.
Personalization and User Engagement
In the realm of media and entertainment, Sora’s ability to analyze and understand audience preferences at a granular level will enable unprecedented levels of content personalization. Media companies can leverage Sora to tailor content to individual user preferences, improving engagement and user satisfaction. This could manifest in personalized news feeds, customized entertainment recommendations, or even dynamically generated content that adapts to the user’s interests and behaviors. Such personalization capabilities are likely to redefine the standards for user experience in digital media platforms. So, let’s dive a bit deeper into how this technology can advance personalization and user engagement within the marketplace.
Examples of Personalization and User Engagement
1. Personalized News Aggregation:
Pros: Platforms can use Sora to curate news content tailored to the individual interests and reading habits of each user. For example, a user interested in technology and sustainability might receive a news feed focused on the latest in green tech innovations, while someone interested in finance and sports might see articles on sports economics. This not only enhances user engagement but also increases the time spent on the platform.
Cons: Over-personalization can lead to the creation of “filter bubbles,” where users are exposed only to viewpoints and topics that align with their existing beliefs and interests. This can narrow the diversity of content consumed and potentially exacerbate societal divisions.
2. Customized Learning Experiences:
Pros: Educational platforms can leverage Sora to adapt learning materials to the pace and learning style of each student. For instance, a visual learner might receive more infographic-based content, while a verbal learner gets detailed textual explanations. This can improve learning outcomes and student engagement.
Cons: There’s a risk of over-reliance on automated personalization, which might overlook the importance of exposing students to challenging materials that are outside their comfort zones, potentially limiting their learning scope.
3. Dynamic Content Generation for Entertainment:
Pros: Streaming services can use Sora to dynamically alter storylines, music, or visual elements based on user preferences. For example, a streaming platform could offer multiple storyline outcomes in a series, allowing users to experience a version that aligns with their interests or past viewing behaviors.
Cons: This level of personalization might reduce the shared cultural experiences that traditional media offers, as audiences fragment across personalized content paths. It could also challenge creators’ artistic visions when content is too heavily influenced by algorithms.
4. Interactive Advertising:
Pros: Advertisers can utilize Sora to create highly targeted and interactive ad content that resonates with the viewer’s specific interests and behaviors, potentially increasing conversion rates. For example, an interactive ad could adjust its message or product recommendations in real-time based on how the user interacts with it.
Cons: Highly personalized ads raise privacy concerns, as they rely on extensive data collection and analysis of user behavior. There’s also the risk of user fatigue if ads become too intrusive or overly personalized, leading to negative brand perceptions.
Navigating the Pros and Cons
To maximize the benefits of personalization while mitigating the downsides, content creators and platforms need to adopt a balanced approach. This includes:
Transparency and Control: Providing users with clear information about how their data is used for personalization and offering them control over their personalization settings.
Diversity and Exposure: Implementing algorithms that occasionally introduce content outside of the user’s usual preferences to broaden their exposure and prevent filter bubbles.
Ethical Data Use: Adhering to ethical standards for data collection and use, ensuring user privacy is protected, and being transparent about data handling practices.
While Sora’s capabilities in personalization and user engagement offer exciting opportunities for content and media creation, they also come with significant responsibilities. Balancing personalization benefits with the need for privacy, diversity, and ethical considerations will be key to harnessing this technology effectively.
Expansion of Creative Possibilities
Sora’s potential to generate creative content opens up new possibilities for media creators. This includes the creation of written content, such as articles, stories, and scripts, as well as the generation of artistic elements like graphics, music, and video content. By augmenting human creativity, Sora can help creators explore new ideas, themes, and formats, potentially leading to the emergence of new genres and forms of media. This democratization of content creation could also lower the barriers to entry for aspiring creators, fostering a more diverse and vibrant media landscape. We will dive a bit deeper into these creative possibilities by exploring the Pros and Cons.
Pros:
Enhanced Creative Tools: Sora can act as a powerful tool for creators, offering new ways to generate ideas, draft content, and even create complex narratives. For example, a novelist could use Sora to brainstorm plot ideas or develop character backstories, significantly speeding up the writing process and enhancing the depth of their stories.
Accessibility to Creation: With Sora, individuals who may not have traditional artistic skills or technical expertise can participate in creative endeavors. For instance, someone with a concept for a graphic novel but without the ability to draw could use Sora to generate visual art, making creative expression more accessible to a broader audience.
Innovative Content Formats: Sora’s capabilities could lead to the creation of entirely new content formats that blend text, visuals, and interactive elements in ways previously not possible. Imagine an interactive educational platform where content dynamically adapts to each student’s learning progress and interests, offering a highly personalized and engaging learning experience.
Cons:
Potential for Diminished Human Creativity: There’s a concern that over-reliance on AI for creative processes could diminish the value of human creativity. If AI-generated content becomes indistinguishable from human-created content, it could devalue original human artistry and creativity in the public perception.
Intellectual Property and Originality Issues: As AI-generated content becomes more prevalent, distinguishing between AI-assisted and purely human-created content could become challenging. This raises questions about copyright, ownership, and the originality of AI-assisted works. For example, if a piece of music is composed with the help of Sora, determining the rights and ownership could become complex.
Homogenization of Content: While AI like Sora can generate content based on vast datasets, there’s a risk that it might produce content that leans towards what is most popular or trending, potentially leading to a homogenization of content. This could stifle diversity in creative expression and reinforce existing biases in media and art.
Navigating the Pros and Cons
To harness the creative possibilities of Sora while addressing the challenges, several strategies can be considered:
Promoting Human-AI Collaboration: Encouraging creators to use Sora as a collaborative tool rather than a replacement for human creativity can help maintain the unique value of human artistry. This approach leverages AI to enhance and extend human capabilities, not supplant them.
Clear Guidelines for AI-generated Content: Developing industry standards and ethical guidelines for the use of AI in creative processes can help address issues of copyright and originality. This includes transparently acknowledging the use of AI in the creation of content.
Diversity and Bias Mitigation: Actively working to ensure that AI models like Sora are trained on diverse datasets and are regularly audited for bias can help prevent the homogenization of content and promote a wider range of voices and perspectives in media and art.
Impact on the Economics of Media Production
The efficiencies and capabilities introduced by Sora are likely to have profound implications for the economics of media production. Reduced production costs and shorter development cycles can make content creation more accessible and sustainable, especially for independent creators and smaller media outlets. However, this could also lead to increased competition and a potential oversaturation of content, challenging creators to find new ways to stand out and monetize their work. While this topic is always considered sensitive, if we can look at it from pro versus con perspective, perhaps we can address it with a neutral focus.
Impact on Cost Structures
Pros:
Reduced Production Costs: Sora can automate aspects of content creation, such as writing, editing, and even some elements of video production, reducing the need for large production teams and lowering costs. For example, a digital news outlet could use Sora to generate first drafts of articles based on input data, allowing journalists to focus on adding depth and context, thus speeding up the production process and reducing labor costs.
Efficiency in Content Localization: Media companies looking to expand globally can use Sora to automate the translation and localization of content, making it more cost-effective to reach international audiences. This could significantly lower the barriers to global content distribution.
Cons:
Initial Investment and Training: The integration of Sora into media production workflows requires upfront investment in technology and training for staff. Organizations may face challenges in adapting existing processes to leverage AI capabilities effectively, which could initially increase costs.
Dependence on AI: Over-reliance on AI for content production could lead to a homogenization of content, as algorithms might favor formats and topics that have historically performed well, potentially stifacing creativity and innovation.
Impact on Revenue Models
Pros:
New Monetization Opportunities: Sora enables the creation of personalized content at scale, opening up new avenues for monetization. For instance, media companies could offer premium subscriptions for highly personalized news feeds or entertainment content, adding a new revenue stream.
Enhanced Ad Targeting: The deep understanding of user preferences and behaviors facilitated by Sora can improve ad targeting, leading to higher ad revenues. For example, a streaming service could use viewer data analyzed by Sora to place highly relevant ads, increasing viewer engagement and advertiser willingness to pay.
Cons:
Shift in Consumer Expectations: As consumers get accustomed to personalized and AI-generated content, they might become less willing to pay for generic content offerings. This could pressure media companies to continuously invest in AI to keep up with expectations, potentially eroding profit margins.
Ad Blockers and Privacy Tools: The same technology that allows for enhanced ad targeting might also lead to increased use of ad blockers and privacy tools by users wary of surveillance and data misuse, potentially impacting ad revenue.
Impact on the Competitive Landscape
Pros:
Level Playing Field for Smaller Players: Sora can democratize content production, allowing smaller media companies and independent creators to produce high-quality content at a lower cost. This could lead to a more diverse media landscape with a wider range of voices and perspectives.
Innovation and Differentiation: Companies that effectively integrate Sora into their production processes can innovate faster and differentiate their offerings, capturing market share from competitors who are slower to adapt.
Cons:
Consolidation Risk: Larger companies with more resources to invest in AI could potentially dominate the market, leveraging Sora to produce content more efficiently and at a larger scale than smaller competitors. This could lead to consolidation in the media industry, reducing diversity in content and viewpoints.
Navigating the Pros and Cons
To effectively navigate these economic impacts, media companies and content creators need to:
Invest in skills and training to ensure their teams can leverage AI tools like Sora effectively.
Develop ethical guidelines and transparency around the use of AI in content creation to maintain trust with audiences.
Explore innovative revenue models that leverage the capabilities of AI while addressing consumer concerns about privacy and data use.
Ethical and Societal Considerations
As Sora influences the content and media industry, ethical and societal considerations will come to the forefront. Issues such as copyright, content originality, misinformation, and the impact of personalized content on societal discourse will need to be addressed. Media creators and platforms will have to navigate these challenges carefully, establishing guidelines and practices that ensure responsible use of AI in content creation while fostering a healthy, informed, and engaged public discourse.
Conclusion
Over the next five years, OpenAI’s Sora is poised to significantly impact the content and media creation industry by enhancing creative processes, enabling personalized experiences, and transforming the economics of content production. As these changes unfold, content and media professionals will need to adapt to the evolving landscape, leveraging Sora’s capabilities to enhance creativity and engagement while addressing the ethical and societal implications of AI-driven content creation.
In the rapidly evolving landscape of artificial intelligence (AI) and machine learning (ML), Large Language Models (LLMs) have emerged as groundbreaking tools that can transform the way organizations interact with their data. Among the myriad applications of LLMs, their integration into question-answering systems for private enterprise documents represents a particularly promising avenue. This post delves into how LLMs, when combined with technologies like Retrieval-Augmented Generation (RAG), can revolutionize knowledge management and information retrieval within organizations.
Understanding Large Language Models (LLMs)
Large Language Models are advanced AI models trained on vast amounts of text data. They have the ability to understand and generate human-like text, making them incredibly powerful tools for natural language processing (NLP) tasks. In the context of enterprise applications, LLMs can sift through extensive repositories of documents to find, interpret, and summarize information relevant to a user’s query.
The Emergence of Retrieval-Augmented Generation (RAG) Technology
Retrieval-Augmented Generation technology represents a significant advancement in the field of AI. RAG combines the generative capabilities of LLMs with information retrieval mechanisms. This hybrid approach enables the model to pull in relevant information from a database or document corpus as context before generating a response. For enterprises, this means that an LLM can answer questions not just based on its pre-training but also using the most current, specific data from the organization’s own documents.
Key Topics in Integrating LLMs with RAG for Enterprise Applications
Data Privacy and Security: When dealing with private enterprise documents, maintaining data privacy and security is paramount. Implementations must ensure that access to documents and data processing complies with relevant regulations and organizational policies.
Information Retrieval Efficiency: Efficient retrieval mechanisms are crucial for sifting through large volumes of documents. This includes developing sophisticated indexing strategies and ensuring that the retrieval component of RAG can quickly locate relevant information.
Model Training and Fine-Tuning: Although pre-trained LLMs have vast knowledge, fine-tuning them on specific enterprise documents can significantly enhance their accuracy and relevance in answering queries. This process involves training the model on a subset of the organization’s documents to adapt its responses to the specific context and jargon of the enterprise.
User Interaction and Interface Design: The effectiveness of a question-answering system also depends on its user interface. Designing intuitive interfaces that facilitate easy querying and display answers in a user-friendly manner is essential for adoption and satisfaction.
Scalability and Performance: As organizations grow, their document repositories and the demand for information retrieval will also expand. Solutions must be designed to scale efficiently, both in terms of processing power and the ability to incorporate new documents into the system seamlessly.
Continuous Learning and Updating: Enterprises continuously generate new documents. Incorporating these documents into the knowledge base and ensuring the LLM remains up-to-date requires mechanisms for continuous learning and model updating.
The Impact of LLMs and RAG on Enterprises
The integration of LLMs with RAG technology into enterprise applications promises a revolution in how organizations manage and leverage their knowledge. This approach can significantly reduce the time and effort required to find information, enhance decision-making processes, and ultimately drive innovation. By making vast amounts of data readily accessible and interpretable, these technologies can empower employees at all levels, from executives seeking strategic insights to technical staff looking for specific technical details.
Conclusion
The integration of Large Language Models into applications across various domains, particularly for question answering over private enterprise documents using RAG technology, represents a frontier in artificial intelligence that can significantly enhance organizational efficiency and knowledge management. By understanding the key considerations such as data privacy, information retrieval efficiency, model training, and user interface design, organizations can harness these technologies to transform their information retrieval processes. As we move forward, the ability of enterprises to effectively implement and leverage these advanced AI tools will become a critical factor in their competitive advantage and operational excellence.
The other day we explored AGI and it’s intersection with philosophy, and today we will take that path a bit more in depth. In the rapidly evolving landscape of artificial intelligence, the advent of Artificial General Intelligence (AGI) marks a pivotal milestone, not only in technological innovation but also in our philosophical contemplations about consciousness, reality, and the essence of human cognition. This long-form exploration delves into the profound implications of AGI on our understanding of consciousness, dissecting the intricacies of theoretical frameworks, and shedding light on the potential challenges and vistas that AGI unfolds in philosophical discourse and ethical considerations.
Understanding AGI: The Convergence of Intelligence and Consciousness
At its core, Artificial General Intelligence (AGI) represents a form of AI that can understand, learn, and apply knowledge in a way that is indistinguishable from human intelligence. Unlike narrow AI, which excels in specific tasks, AGI possesses the versatility and adaptability to perform any intellectual task that a human being can. This distinction is crucial, as it propels AGI from the realm of task-specific algorithms to the frontier of true cognitive emulation.
Defining Consciousness in the Context of AGI
Before we can appreciate the implications of AGI on consciousness, we must first define what consciousness entails. Consciousness, in its most encompassing sense, refers to the quality or state of being aware of an external object or something within oneself. It is characterized by perception, awareness, self-awareness, and the capacity to experience feelings and thoughts. In the debate surrounding AGI, consciousness is often discussed in terms of “phenomenal consciousness,” which encompasses the subjective, qualitative aspects of experiences, and “access consciousness,” relating to the cognitive aspects of consciousness that involve reasoning and decision-making.
Theoretical Frameworks Guiding AGI and Consciousness
Several theoretical frameworks have been proposed to understand consciousness in AGI, each offering unique insights into the potential cognitive architectures and processes that might underlie artificial consciousness. These include:
Integrated Information Theory (IIT): Posits that consciousness arises from the integration of information within a system. AGI systems that exhibit high levels of information integration may, in theory, possess a form of consciousness.
Global Workspace Theory (GWT): Suggests that consciousness results from the broadcast of information in the brain (or an AGI system) to a “global workspace,” where it becomes accessible for decision-making and reasoning.
Functionalism: Argues that mental states, including consciousness, are defined by their functional roles in cognitive processes rather than by their internal composition. Under this view, if an AGI system performs functions akin to those associated with human consciousness, it could be considered conscious.
Real-World Case Studies and Practical Applications
Exploring practical applications and case studies of AGI can offer insights into how these theoretical frameworks might be realized. For instance, projects like OpenAI’s GPT series demonstrate how AGI could mimic certain aspects of human thought and language processing, touching upon aspects of access consciousness through natural language understanding and generation. Similarly, AI systems that navigate complex environments or engage in creative problem-solving activities showcase the potential for AGI to exhibit decision-making processes and adaptability indicative of a rudimentary form of consciousness.
Philosophical Implications of AGI
The emergence of AGI challenges our deepest philosophical assumptions about consciousness, free will, and the nature of reality.
Challenging Assumptions about Consciousness and Free Will
AGI prompts us to reconsider the boundaries of consciousness. If an AGI system exhibits behaviors and decision-making processes that mirror human consciousness, does it possess consciousness in a comparable sense? Furthermore, the development of AGI raises questions about free will and autonomy, as the actions of a seemingly autonomous AGI system could blur the lines between programmed responses and genuine free-willed decisions.
Rethinking the Nature of Reality
AGI also invites a reevaluation of our understanding of reality. The ability of AGI systems to simulate complex environments and interactions could lead to philosophical inquiries about the distinctions between simulated realities and our own perceived reality, challenging our preconceptions about the nature of existence itself.
The Role of Philosophy in the Ethical Development of AI
Philosophy plays a crucial role in guiding the ethical development and deployment of AGI. By grappling with questions of consciousness, personhood, and moral responsibility, philosophy can inform the creation of ethical frameworks that ensure AGI technologies are developed and used in ways that respect human dignity and promote societal well-being.
Navigating the Future with Ethical Insight
As we stand on the brink of realizing Artificial General Intelligence, it is imperative that we approach this frontier with a blend of technological innovation and philosophical wisdom. The exploration of AGI’s implications on our understanding of consciousness underscores the need for a multidisciplinary approach, marrying the advancements in AI with deep ethical and philosophical inquiry. By doing so, we can navigate the complexities of AGI, ensuring that as we forge ahead into this uncharted territory, we do so with a keen awareness of the ethical considerations and philosophical questions that accompany the development of technologies with the potential to redefine the very essence of human cognition and consciousness.
As AGI continues to evolve, its potential impact on philosophical thought and debate becomes increasingly significant. The exploration of consciousness through the lens of AGI not only challenges our existing notions of what it means to be conscious but also opens up new avenues for understanding the intricacies of the human mind. This interplay between technology and philosophy offers a unique opportunity to expand our conceptual frameworks and to ponder the profound questions that have perplexed humanity for centuries.
The Integration of Philosophy and AGI Development
The ethical development of AGI necessitates a collaborative effort between technologists, philosophers, and ethicists. This collaboration is essential for addressing the multifaceted challenges posed by AGI, including issues of privacy, autonomy, and the potential societal impacts of widespread AGI deployment. By integrating philosophical insights into the development process, we can create AGI systems that not only excel in cognitive tasks but also adhere to ethical standards that prioritize human values and rights.
Future Directions: Ethical AGI and Beyond
Looking forward, the journey towards ethically responsible AGI will involve continuous dialogue and reassessment of our ethical frameworks in light of new developments and understandings. As AGI systems become more advanced and their capabilities more closely resemble those of human intelligence, the importance of grounding these technologies in a solid ethical foundation cannot be overstated. This involves not only addressing the immediate implications of AGI but also anticipating future challenges and ensuring that AGI development is aligned with long-term human interests and well-being.
Furthermore, the exploration of AGI and consciousness offers the possibility of gaining new insights into the nature of human intelligence and the universe itself. By examining the parallels and differences between human and artificial consciousness, we can deepen our understanding of what it means to be conscious entities and explore new dimensions of our existence.
Conclusion: A Call for Ethical Vigilance and Philosophical Inquiry
The advent of AGI represents a watershed moment in the history of technology and philosophy. As we navigate the complexities and opportunities presented by AGI, it is crucial that we do so with a commitment to ethical integrity and philosophical depth. The exploration of AGI’s implications on consciousness and reality invites us to engage in rigorous debate, to question our assumptions, and to seek a deeper understanding of our place in the cosmos.
In conclusion, the development of AGI challenges us to look beyond the technical achievements and to consider the broader philosophical and ethical implications of creating entities that may one day rival or surpass human intelligence. By fostering a culture of ethical vigilance and philosophical inquiry, we can ensure that the journey towards AGI is one that benefits all of humanity, paving the way for a future where technology and human values coalesce to create a world of unprecedented possibility and understanding.
In the rapidly evolving landscape of Artificial Intelligence (AI), the significance of AI modeling cannot be overstated. At the heart of AI’s transformative power are the models that learn from data to make predictions or decisions without being explicitly programmed for the task. This blog post delves deep into the essence of unsupervised training, a cornerstone of AI modeling, exploring its impact on scalability, richer understanding, versatility, and efficiency. Our aim is to equip practitioners with a comprehensive understanding of AI modeling, enabling them to discuss its intricacies and practical applications in the technology and business realms with confidence.
Understanding Unsupervised Training in AI Modeling
Unsupervised training is a type of machine learning that operates without labeled outcomes. Unlike supervised learning, where models learn from input-output pairs, unsupervised learning algorithms analyze and cluster untagged data based on inherent patterns and similarities. This method is pivotal in discovering hidden structures within data, making it indispensable for tasks such as anomaly detection, clustering, and dimensionality reduction.
Deep Dive into Unsupervised Training in AI Modeling
Unsupervised training represents a paradigm within artificial intelligence where models learn patterns from untagged data, offering a way to glean insights without the need for explicit instructions. This method plays a pivotal role in understanding complex datasets, revealing hidden structures that might not be immediately apparent. To grasp the full scope of unsupervised training, it’s essential to explore its advantages and challenges, alongside illustrative examples that showcase its practical applications.
Advantages of Unsupervised Training
Discovery of Hidden Patterns: Unsupervised learning excels at identifying subtle, underlying patterns and relationships in data that might not be recognized through human analysis or supervised methods. This capability is invaluable for exploratory data analysis and understanding complex datasets.
Efficient Use of Unlabeled Data: Since unsupervised training doesn’t require labeled datasets, it makes efficient use of the vast amounts of untagged data available. This aspect is particularly beneficial in fields where labeled data is scarce or expensive to obtain.
Flexibility and Adaptability: Unsupervised models can adapt to changes in the data without needing retraining with a new set of labeled data. This makes them suitable for dynamic environments where data patterns and structures may evolve over time.
Challenges of Unsupervised Training
Interpretation of Results: The outcomes of unsupervised learning can sometimes be ambiguous or difficult to interpret. Without predefined labels to guide the analysis, determining the significance of the patterns found by the model requires expert knowledge and intuition.
Risk of Finding Spurious Relationships: Without the guidance of labeled outcomes, unsupervised models might identify patterns or clusters that are statistically significant but lack practical relevance or are purely coincidental.
Parameter Selection and Model Complexity: Choosing the right parameters and model complexity for unsupervised learning can be challenging. Incorrect choices can lead to overfitting, where the model captures noise instead of the underlying distribution, or underfitting, where the model fails to capture the significant structure of the data.
Examples of Unsupervised Training in Action
Customer Segmentation in Retail: Retail companies use unsupervised learning to segment their customers based on purchasing behavior, frequency, and preferences. Clustering algorithms like K-means can group customers into segments, helping businesses tailor their marketing strategies to each group’s unique characteristics.
Anomaly Detection in Network Security: Unsupervised models are deployed to monitor network traffic and identify unusual patterns that could indicate a security breach. By learning the normal operation pattern, the model can flag deviations, such as unusual login attempts or spikes in data traffic, signaling potential security threats.
Recommendation Systems: Many recommendation systems employ unsupervised learning to identify items or content similar to what a user has liked in the past. By analyzing usage patterns and item features, these systems can uncover relationships between different products or content, enhancing the personalization of recommendations.
Unsupervised training in AI modeling offers a powerful tool for exploring and understanding data. Its ability to uncover hidden patterns without the need for labeled data presents both opportunities and challenges. While the interpretation of its findings demands a nuanced understanding, and the potential for identifying spurious relationships exists, the benefits of discovering new insights and efficiently utilizing unlabeled data are undeniable. Through examples like customer segmentation, anomaly detection, and recommendation systems, we see the practical value of unsupervised training in driving innovation and enhancing decision-making across industries. As we continue to refine these models and develop better techniques for interpreting their outputs, unsupervised training will undoubtedly remain a cornerstone of AI research and application.
The Significance of Scalability and Richer Understanding
Scalability in AI modeling refers to the ability of algorithms to handle increasing amounts of data and complexity without sacrificing performance. Unsupervised learning, with its capacity to sift through vast datasets and uncover relationships without prior labeling, plays a critical role in enhancing scalability. It enables models to adapt to new data seamlessly, facilitating the development of more robust and comprehensive AI systems.
Furthermore, unsupervised training contributes to a richer understanding of data. By analyzing datasets in their raw, unlabelled form, these models can identify nuanced patterns and correlations that might be overlooked in supervised settings. This leads to more insightful and detailed data interpretations, fostering innovations in AI applications.
Versatility and Efficiency: Unlocking New Potentials
Unsupervised learning is marked by its versatility, finding utility across various sectors, including finance for fraud detection, healthcare for patient segmentation, and retail for customer behavior analysis. This versatility stems from the method’s ability to learn from data without needing predefined labels, making it applicable to a wide range of scenarios where obtaining labeled data is impractical or impossible.
Moreover, unsupervised training enhances the efficiency of AI modeling. By eliminating the need for extensive labeled datasets, which are time-consuming and costly to produce, it accelerates the model development process. Additionally, unsupervised models can process and analyze data in real-time, providing timely insights that are crucial for dynamic and fast-paced environments.
Practical Applications and Future Outlook
The practical applications of unsupervised learning in AI are vast and varied. In the realm of customer experience management, for instance, unsupervised models can analyze customer feedback and behavior patterns to identify unmet needs and tailor services accordingly. In the context of digital transformation, these models facilitate the analysis of large datasets to uncover trends and insights that drive strategic decisions.
Looking ahead, the role of unsupervised training in AI modeling is set to become even more prominent. As the volume of data generated by businesses and devices continues to grow exponentially, the ability to efficiently process and derive value from this data will be critical. Unsupervised learning, with its scalability, versatility, and efficiency, is poised to be at the forefront of this challenge, driving advancements in AI that we are only beginning to imagine.
Conclusion
Unsupervised training in AI modeling is more than just a method; it’s a catalyst for innovation and understanding in the digital age. Its impact on scalability, richer understanding, versatility, and efficiency underscores its importance in the development of intelligent systems. For practitioners in the field of AI, mastering the intricacies of unsupervised learning is not just beneficial—it’s essential. As we continue to explore the frontiers of AI, the insights and capabilities unlocked by unsupervised training will undoubtedly shape the future of technology and business.
By delving into the depths of AI modeling, particularly through the lens of unsupervised training, we not only enhance our understanding of artificial intelligence but also unlock new potentials for its application across industries. The journey towards mastering AI modeling is complex, yet it promises a future where the practicality and transformative power of AI are realized to their fullest extent.
In the rapidly evolving landscape of artificial intelligence, the development of generative text models represents a significant milestone, offering unprecedented capabilities in natural language understanding and generation. Among these advancements, Llama 2 emerges as a pivotal innovation, setting new benchmarks for AI-assisted interactions and a wide array of natural language processing tasks. This blog post delves into the intricacies of Llama 2, exploring its creation, the vision behind it, its developers, and the potential trajectory of these models in shaping the future of AI. But let’s start from the beginning of Generative AI models.
Generative AI Models: A Historical Overview
The landscape of generative AI models has rapidly evolved, with significant milestones marking the journey towards more sophisticated, efficient, and versatile AI systems. Starting from the introduction of simple neural networks to the development of transformer-based models like OpenAI’s GPT (Generative Pre-trained Transformer) series, AI research has continually pushed the boundaries of what’s possible with natural language processing (NLP).
The Vision and Creation of Advanced Models
The creation of advanced generative models has been motivated by a desire to overcome the limitations of earlier AI systems, including challenges related to understanding context, generating coherent long-form content, and adapting to various languages and domains. The vision behind these developments has been to create AI that can seamlessly interact with humans, provide valuable insights, and assist in creative and analytical tasks with unprecedented accuracy and flexibility.
Key Contributors and Collaborations
The development of cutting-edge AI models has often been the result of collaborative efforts involving researchers from academic institutions, tech companies, and independent AI research organizations. For instance, OpenAI’s GPT series was developed by a team of researchers and engineers committed to advancing AI in a way that benefits humanity. Similarly, other organizations like Google AI (with models like BERT and T5) and Facebook AI (with models like RoBERTa) have made significant contributions to the field.
The Creation Process and Technological Innovations
The creation of these models involves leveraging large-scale datasets, sophisticated neural network architectures (notably the transformer model), and innovative training techniques. Unsupervised learning plays a critical role, allowing models to learn from vast amounts of text data without explicit labeling. This approach enables the models to understand linguistic patterns, context, and subtleties of human language.
Unsupervised learning is a type of machine learning algorithm that plays a fundamental role in the development of advanced generative text models, such as those described in our discussions around “Llama 2” or similar AI technologies. Unlike supervised learning, which relies on labeled datasets to teach models how to predict outcomes based on input data, unsupervised learning does not use labeled data. Instead, it allows the model to identify patterns, structures, and relationships within the data on its own. This distinction is crucial for understanding how AI models can learn and adapt to a wide range of tasks without extensive manual intervention.
Understanding Unsupervised Learning
Unsupervised learning involves algorithms that are designed to work with datasets that do not have predefined or labeled outcomes. The goal of these algorithms is to explore the data and find some structure within. This can involve grouping data into clusters (clustering), estimating the distribution within the data (density estimation), or reducing the dimensionality of data to understand its structure better (dimensionality reduction).
Importance in AI Model Building
The critical role of unsupervised learning in building generative text models, such as those employed in natural language processing (NLP) tasks, stems from several factors:
Scalability: Unsupervised learning can handle vast amounts of data that would be impractical to label manually. This capability is essential for training models on the complexities of human language, which requires exposure to diverse linguistic structures, idioms, and cultural nuances.
Richer Understanding: By learning from data without pre-defined labels, models can develop a more nuanced understanding of language. They can discover underlying patterns, such as syntactic structures and semantic relationships, which might not be evident through supervised learning alone.
Versatility: Models trained using unsupervised learning can be more adaptable to different types of tasks and data. This flexibility is crucial for generative models expected to perform a wide range of NLP tasks, from text generation to sentiment analysis and language translation.
Efficiency: Collecting and labeling large datasets is time-consuming and expensive. Unsupervised learning mitigates this by leveraging unlabeled data, significantly reducing the resources needed to train models.
Practical Applications
In the context of AI and NLP, unsupervised learning is used to train models on the intricacies of language without explicit instruction. For example, a model might learn to group words with similar meanings or usage patterns together, recognize the structure of sentences, or generate coherent text based on the patterns it has discovered. This approach is particularly useful for generating human-like text, understanding context in conversations, or creating models that can adapt to new, unseen data with minimal additional training.
Unsupervised learning represents a cornerstone in the development of generative text models, enabling them to learn from the vast and complex landscape of human language without the need for labor-intensive labeling. By allowing models to uncover hidden patterns and relationships in data, unsupervised learning not only enhances the models’ understanding and generation of language but also paves the way for more efficient, flexible, and scalable AI solutions. This methodology underpins the success and versatility of advanced AI models, driving innovations that continue to transform the field of natural language processing and beyond.
The Vision for the Future
The vision upon the creation of models akin to “Llama 2” has been to advance AI to a point where it can understand and generate human-like text across various contexts and tasks, making AI more accessible, useful, and transformative across different sectors. This includes improving customer experience through more intelligent chatbots, enhancing creativity and productivity in content creation, and providing sophisticated tools for data analysis and decision-making.
Ethical Considerations and Future Directions
The creators of these models are increasingly aware of the ethical implications, including the potential for misuse, bias, and privacy concerns. As a result, the vision for future models includes not only technological advancements but also frameworks for ethical AI use, transparency, and safety measures to ensure these tools contribute positively to society.
Introduction to Llama 2
Llama 2 is a state-of-the-art family of generative text models, meticulously optimized for assistant-like chat use cases and adaptable across a spectrum of natural language generation (NLG) tasks. It stands as a beacon of progress in the AI domain, enhancing machine understanding and responsiveness to human language. Llama 2’s design philosophy and architecture are rooted in leveraging deep learning to process and generate text with a level of coherence, relevancy, and contextuality previously unattainable.
The Genesis of Llama 2
The inception of Llama 2 was driven by the pursuit of creating more efficient, accurate, and versatile AI models capable of understanding and generating human-like text. This initiative was spurred by the limitations observed in previous generative models, which, despite their impressive capabilities, often struggled with issues of context retention, task flexibility, and computational efficiency.
The development of Llama 2 was undertaken by a collaborative effort among leading researchers in artificial intelligence and computational linguistics. These experts sought to address the shortcomings of earlier models by incorporating advanced neural network architectures, such as transformer models, and refining training methodologies to enhance language understanding and generation capabilities.
Architectural Innovations and Training
Llama 2’s architecture is grounded in the transformer model, renowned for its effectiveness in handling sequential data and its capacity for parallel processing. This choice facilitates the model’s ability to grasp the nuances of language and maintain context over extended interactions. Furthermore, Llama 2 employs cutting-edge techniques in unsupervised learning, leveraging vast datasets to refine its understanding of language patterns, syntax, semantics, and pragmatics.
The training process of Llama 2 involves feeding the model a diverse array of text sources, from literature and scientific articles to web content and dialogue exchanges. This exposure enables the model to learn a broad spectrum of language styles, topics, and user intents, thereby enhancing its adaptability and performance across different tasks and domains.
Practical Applications and Real-World Case Studies
Llama 2’s versatility is evident through its wide range of applications, from enhancing customer service through AI-powered chatbots to facilitating content creation, summarization, and language translation. Its ability to understand and generate human-like text makes it an invaluable tool in various sectors, including healthcare, education, finance, and entertainment.
One notable case study involves the deployment of Llama 2 in a customer support context, where it significantly improved response times and satisfaction rates by accurately interpreting customer queries and generating coherent, contextually relevant responses. Another example is its use in content generation, where Llama 2 assists writers and marketers by providing creative suggestions, drafting articles, and personalizing content at scale.
The Future of Llama 2 and Beyond
The trajectory of Llama 2 and similar generative models points towards a future where AI becomes increasingly integral to our daily interactions and decision-making processes. As these models continue to evolve, we can anticipate enhancements in their cognitive capabilities, including better understanding of nuanced human emotions, intentions, and cultural contexts.
Moreover, ethical considerations and the responsible use of AI will remain paramount, guiding the development of models like Llama 2 to ensure they contribute positively to society and foster trust among users. The ongoing collaboration between AI researchers, ethicists, and industry practitioners will be critical in navigating these challenges and unlocking the full potential of generative text models.
Conclusion
Llama 2 represents a significant leap forward in the realm of artificial intelligence, offering a glimpse into the future of human-machine interaction. By understanding its development, architecture, and applications, AI practitioners and enthusiasts can appreciate the profound impact of these models on various industries and aspects of our lives. As we continue to explore and refine the capabilities of Llama 2, the potential for creating more intelligent, empathetic, and efficient AI assistants seems boundless, promising to revolutionize the way we communicate, learn, and solve problems in the digital age.
In essence, Llama 2 is not just a technological achievement; it’s a stepping stone towards realizing the full potential of artificial intelligence in enhancing human experiences and capabilities. As we move forward, the exploration and ethical integration of models like Llama 2 will undoubtedly play a pivotal role in shaping the future of AI and its contribution to society. If you are interested in deeper dives into Llama 2 or generative AI models, please let us know and the team can continue discussions at a more detailed level.
Recently, there has been a buzz about AI replacing workers in various industries. While some of this disruption has been expected, or even planned, there are some that have become increasingly concerned on how far this trend will spread. In today’s post, we will highlight a few industries where this discussion appears to be the most active.
The advent of artificial intelligence (AI) has ushered in a transformative era across various industries, fundamentally reshaping business landscapes and operational paradigms. As AI continues to evolve, certain careers, notably in real estate, banking, and journalism, face significant disruption. In this blog post, we will explore the impact of AI on these sectors, identify the aspects that make these careers vulnerable, and conclude with strategic insights for professionals aiming to stay relevant and valuable in their fields.
Real Estate: The AI Disruption
In the real estate sector, AI’s integration has been particularly impactful in areas such as property valuation, predictive analytics, and virtual property tours. AI algorithms can analyze vast data sets, including historical transaction records and real-time market trends, to provide more accurate property appraisals and investment insights. This diminishes the traditional role of real estate agents in providing market expertise.
Furthermore, AI-powered chatbots and virtual assistants are enhancing customer engagement and streamlining administrative tasks, reducing the need for human intermediaries in initial client interactions and basic inquiries. Virtual reality (VR) and augmented reality (AR) technologies are enabling immersive property tours, diminishing the necessity of physical site visits and the agent’s role in showcasing properties.
The real estate industry, traditionally reliant on personal relationships and local market knowledge, is undergoing a significant transformation due to the advent and evolution of artificial intelligence (AI). This shift not only affects current practices but also has the potential to reshape the industry for generations to come. Let’s explore the various dimensions in which AI is influencing real estate, with a focus on its implications for agents and brokers.
1. Property Valuation and Market Analysis
AI-powered algorithms have revolutionized property valuation and market analysis. By processing vast amounts of data, including historical sales, neighborhood trends, and economic indicators, these algorithms can provide highly accurate property appraisals and market forecasts. This diminishes the traditional role of agents and brokers in manually analyzing market data and estimating property values.
Example: Zillow’s Zestimate tool uses machine learning to estimate home values based on public and user-submitted data, offering instant appraisals without the need for agent intervention.
2. Lead Generation and Customer Relationship Management
AI-driven customer relationship management (CRM) systems are transforming lead generation and client interaction in real estate. These systems can predict which clients are more likely to buy or sell based on behavioral data, significantly enhancing the efficiency of lead generation. They also automate follow-up communications and personalize client interactions, reducing the time agents spend on routine tasks.
Example: CRM platforms like Chime use AI to analyze user behavior on real estate websites, helping agents identify and target potential leads more effectively.
3. Virtual Property Showings and Tours
AI, in conjunction with VR and AR, is enabling virtual property showings and tours. Potential buyers can now tour properties remotely, reducing the need for agents to conduct multiple in-person showings. This technology is particularly impactful in the current era of social distancing and has the potential to become a standard practice in the future.
Example: Matterport’s 3D technology allows for the creation of virtual tours, giving prospective buyers a realistic view of properties from their own homes.
4. Transaction and Document Automation
AI is streamlining real estate transactions by automating document processing and legal formalities. Smart contracts, powered by blockchain technology, are automating contract execution and reducing the need for intermediaries in transactions.
Example: Platforms like Propy utilize blockchain to facilitate secure and automated real estate transactions, potentially reducing the role of agents in the closing process.
5. Predictive Analytics in Real Estate Investment
AI’s predictive analytics capabilities are reshaping real estate investment strategies. Investors can use AI to analyze market trends, forecast property value appreciation, and identify lucrative investment opportunities, which were traditionally areas where agents provided expertise.
Example: Companies like HouseCanary offer predictive analytics tools that analyze millions of data points to forecast real estate market trends and property values.
Impact on Agents and Brokers: Navigating the Changing Tides
The generational impact of AI in real estate will likely manifest in several ways:
Skillset Shift: Agents and brokers will need to adapt their skillsets to focus more on areas where human expertise is crucial, such as negotiation, relationship-building, and local market knowledge that AI cannot replicate.
Role Transformation: The traditional role of agents as information gatekeepers will evolve. They will need to position themselves as advisors and consultants, leveraging AI tools to enhance their services rather than being replaced by them.
Educational and Training Requirements: Future generations of real estate professionals will likely require education and training that emphasize digital literacy, understanding AI tools, and data analytics, in addition to traditional real estate knowledge.
Competitive Landscape: The real estate industry will become increasingly competitive, with a higher premium placed on agents who can effectively integrate AI into their practices.
AI’s influence on the real estate industry is profound, necessitating a fundamental shift in the roles and skills of agents and brokers. By embracing AI and adapting to these changes, real estate professionals can not only survive but thrive in this new landscape, leveraging AI to provide enhanced services and value to their clients.
Banking: AI’s Transformative Impact
The banking sector is experiencing a paradigm shift due to AI-driven innovations in areas like risk assessment, fraud detection, and personalized customer service. AI algorithms excel in analyzing complex financial data, identifying patterns, and predicting risks, thus automating decision-making processes in credit scoring and loan approvals. This reduces the reliance on financial analysts and credit officers.
Additionally, AI-powered chatbots and virtual assistants are revolutionizing customer service, offering 24/7 support and personalized financial advice. This automation and personalization reduce the need for traditional customer service roles in banking. Moreover, AI’s role in fraud detection and prevention, through advanced pattern recognition and anomaly detection, is minimizing the need for extensive manual monitoring.
This technological revolution is not just reshaping current roles and operations but also has the potential to redefine the industry for future generations. Let’s explore the various ways in which AI is influencing the banking sector and its implications for existing roles, positions, and careers.
1. Credit Scoring and Risk Assessment
AI has significantly enhanced the efficiency and accuracy of credit scoring and risk assessment processes. Traditional methods relied heavily on manual analysis of credit histories and financial statements. AI algorithms, however, can analyze a broader range of data, including non-traditional sources such as social media activity and online behavior, to provide a more comprehensive risk profile.
Example: FICO, known for its credit scoring model, uses machine learning to analyze alternative data sources for assessing creditworthiness, especially useful for individuals with limited credit histories.
2. Fraud Detection and Prevention
AI-driven systems are revolutionizing fraud detection and prevention in banking. By using advanced machine learning algorithms, these systems can identify patterns and anomalies indicative of fraudulent activity, often in real-time, significantly reducing the incidence of fraud.
Example: Mastercard uses AI-powered systems to analyze transaction data across its network, enabling the detection of fraudulent transactions with greater accuracy and speed.
3. Personalized Banking Services
AI is enabling the personalization of banking services, offering customers tailored financial advice, product recommendations, and investment strategies. This level of personalization was traditionally the domain of personal bankers and financial advisors.
Example: JPMorgan Chase uses AI to analyze customer data and provide personalized financial insights and recommendations through its mobile app.
4. Customer Service Automation
AI-powered chatbots and virtual assistants are transforming customer service in banking. These tools can handle a wide range of customer inquiries, from account balance queries to complex transaction disputes, which were previously managed by customer service representatives.
Robotic Process Automation (RPA) and AI are automating routine tasks such as data entry, report generation, and compliance checks. This reduces the need for manual labor in back-office operations and shifts the focus of employees to more strategic and customer-facing roles.
Example: HSBC uses RPA and AI to automate mundane tasks, allowing employees to focus on more complex and value-added activities.
Beyond Suits and Spreadsheets
The generational impact of AI in banking will likely result in several key changes:
Skillset Evolution: Banking professionals will need to adapt their skillsets to include digital literacy, understanding of AI and data analytics, and adaptability to technological changes.
Role Redefinition: Traditional roles, particularly in customer service and back-office operations, will evolve. Banking professionals will need to focus on areas where human judgment and expertise are critical, such as complex financial advisory and relationship management.
Career Path Changes: Future generations entering the banking industry will likely find a landscape where AI and technology skills are as important as traditional banking knowledge. Careers will increasingly blend finance with technology.
New Opportunities: AI will create new roles in data science, AI ethics, and AI integration. There will be a growing demand for professionals who can bridge the gap between technology and banking.
AI’s influence on the banking industry will be thorough and multifaceted, necessitating a significant shift in the roles, skills, and career paths of banking professionals. By embracing AI, adapting to technological changes, and focusing on areas where human expertise is crucial, banking professionals can not only remain relevant but also drive innovation and growth in this new era.
Journalism: The AI Challenge
In journalism, AI’s emergence is particularly influential in content creation, data journalism, and personalized news delivery. Automated writing tools, using natural language generation (NLG) technologies, can produce basic news articles, particularly in areas like sports and finance, where data-driven reports are prevalent. This challenges the traditional role of journalists in news writing and reporting.
AI-driven data journalism tools can analyze large data sets to uncover trends and insights, tasks that were traditionally the domain of investigative journalists. Personalized news algorithms are tailoring content delivery to individual preferences, reducing the need for human curation in newsrooms.
This technological shift is not just altering current journalistic practices but is also poised to redefine the landscape for future generations in the field. Let’s delve into the various ways AI is influencing journalism and its implications for existing roles, positions, and careers.
1. Automated Content Creation
One of the most notable impacts of AI in journalism is automated content creation, also known as robot journalism. AI-powered tools use natural language generation (NLG) to produce news articles, especially for routine and data-driven stories such as sports recaps, financial reports, and weather updates.
Example: The Associated Press uses AI to automate the writing of earnings reports and minor league baseball stories, significantly increasing the volume of content produced with minimal human intervention.
2. Enhanced Research and Data Journalism
AI is enabling more sophisticated research and data journalism by analyzing large datasets to uncover trends, patterns, and stories. This capability was once the sole domain of investigative journalists who spent extensive time and effort in data analysis.
Example: Reuters uses an AI tool called Lynx Insight to assist journalists in analyzing data, suggesting story ideas, and even writing some parts of articles.
3. Personalized News Delivery
AI algorithms are increasingly used to curate and personalize news content for readers, tailoring news feeds based on individual preferences, reading habits, and interests. This reduces the reliance on human editors for content curation and distribution.
Example: The New York Times uses AI to personalize article recommendations on its website and apps, enhancing reader engagement and experience.
4. Fact-Checking and Verification
AI tools are aiding journalists in the crucial task of fact-checking and verifying information. By quickly analyzing vast amounts of data, AI can identify inconsistencies, verify sources, and cross-check facts, a process that was traditionally time-consuming and labor-intensive.
Example: Full Fact, a UK-based fact-checking organization, uses AI to monitor live TV and online news streams to fact-check in real time.
5. Audience Engagement and Analytics
AI is transforming how media organizations understand and engage with their audiences. By analyzing reader behavior, preferences, and feedback, AI tools can provide insights into content performance and audience engagement, guiding editorial decisions.
Example: The Washington Post uses its in-house AI technology, Heliograf, to analyze reader engagement and suggest ways to optimize content for better performance.
The Evolving Landscape of Journalism Careers
The generational impact of AI in journalism will likely manifest in several ways:
Skillset Adaptation: Journalists will need to develop digital literacy, including a basic understanding of AI, data analytics, and multimedia storytelling.
Role Transformation: Traditional roles in journalism will evolve, with a greater emphasis on investigative reporting, in-depth analysis, and creative storytelling — areas where AI cannot fully replicate human capabilities.
Educational Shifts: Journalism education and training will increasingly incorporate AI, data journalism, and technology skills alongside core journalistic principles.
New Opportunities: AI will create new roles within journalism, such as AI newsroom liaisons, data journalists, and digital content strategists, who can blend journalistic skills with technological expertise.
Ethical Considerations: Journalists will play a crucial role in addressing the ethical implications of AI in news production, including biases in AI algorithms and the impact on public trust in media.
AI’s impact on the journalism industry will be extreme, bringing both challenges and opportunities. Journalists who embrace AI, adapt their skillsets, and focus on areas where human expertise is paramount can navigate this new landscape successfully. By doing so, they can leverage AI to enhance the quality, efficiency, and reach of their work, ensuring that journalism continues to fulfill its vital role in society.
Strategies for Remaining Relevant
To remain valuable in these evolving sectors, professionals need to focus on developing skills that AI cannot easily replicate. This includes:
Emphasizing Human Interaction and Empathy: In real estate, building strong client relationships and offering personalized advice based on clients’ unique circumstances will be crucial. Similarly, in banking and journalism, the human touch in understanding customer needs and providing insightful analysis will remain invaluable.
Leveraging AI to Enhance Skill Sets: Professionals should embrace AI as a tool to augment their capabilities. Real estate agents can use AI for market analysis but add value through their negotiation skills and local market knowledge. Bankers can leverage AI for efficiency but focus on complex financial advisory roles. Journalists can use AI for routine reporting but concentrate on in-depth investigative journalism and storytelling.
Continuous Learning and Adaptation: Staying abreast of technological advancements and continuously upgrading skills are essential. This includes understanding AI technologies, data analytics, and digital tools relevant to each sector.
Fostering Creativity and Strategic Thinking: AI struggles with tasks requiring creativity, critical thinking, and strategic decision-making. Professionals who can think innovatively and strategically will continue to be in high demand.
Conclusion
The onset of AI presents both challenges and opportunities. For professionals in real estate, banking, and journalism, the key to staying relevant lies in embracing AI’s capabilities, enhancing their unique human skills, and continuously adapting to the evolving technological landscape. By doing so, they can transform these challenges into opportunities for growth and innovation. Please consider following our posts, as we continue to blend technology trends with discussions taking place online and in the office.