The team is back from a well-deserved Spring Break, they insist they are re-energized and ready to discuss all that 2026 has to throw at them. So, let’s test them out and throw them right into the Tech Craziness. Today, we start with a topic that continues to raise its head-scratching theme of “Vibe Coding”. If you remember, we wrote a post on January 25th of this year, touching on the topic. In today’s publication….we will dive just a bit deeper.
Introduction
In the previous discussion, Vibe Coding: When Intent Becomes the Interface, we established the premise that modern software creation is shifting from syntax-driven execution to intent-driven orchestration. This follow-on expands that foundation into practical application. The focus here is progression: how to refine outputs, how to operate effectively in real environments, and how to evolve into someone who can scale and teach the discipline.
1. Refining the Craft: How to “Tune” Vibe Coding
At a surface level, vibe coding appears deceptively simple: describe intent, receive output. In practice, high-quality results are the product of structured refinement loops.
1.1 Precision Framing Over Prompting
The most common failure mode is under-specification. Strong practitioners treat prompts less like instructions and more like mini design briefs.
Example evolution:
Weak: “Build a dashboard for customer data”
Intermediate: “Create a dashboard showing churn rate, NPS, and support volume trends”
Advanced: “Build a customer experience dashboard for a telecom operator that tracks churn, NPS, and call center volume. Include time-series analysis, cohort segmentation, and anomaly detection flags. Optimize for executive consumption.”
The difference is not verbosity, but clarity of:
Outcome
Audience
Constraints
Decision utility
1.2 Iterative Decomposition
Experienced practitioners rarely expect a single-pass result.
Instead, they:
Generate a baseline artifact
Decompose into modules (UI, logic, data, edge cases)
Refine each component independently
This mirrors agile development, but compressed into conversational cycles.
1.3 Constraint Injection
Vibe coding improves significantly when constraints are explicitly introduced:
Vibe coding represents a fundamental shift in how digital systems are created and managed. It lowers the barrier to entry, accelerates iteration, and reshapes the relationship between humans and machines.
However, its true value is not in replacing traditional development, but in augmenting it. The practitioners who will lead this space are those who can balance speed with structure, creativity with control, and automation with accountability.
For those willing to invest in both the craft and the discipline, vibe coding is not just a skill. It is an emerging layer of digital fluency that will define how organizations build, adapt, and compete in the next phase of technological evolution.
Follow us on (Spotify) as we discuss this topic more in depth along with other topics that our readers have found interest in.
The collaboration between OpenAI and OpenClaw is significant because it represents a convergence of two critical layers in the evolving AI stack: advanced cognitive intelligence and autonomous execution. Historically, one domain has focused on building systems that can reason, learn, and generalize, while the other has focused on turning that intelligence into persistent, goal-directed action across real digital environments. Bringing these capabilities closer together accelerates the transition from AI as a responsive tool to AI as an operational system capable of planning, executing, and adapting over time. This has implications far beyond technical progress, influencing platform control, automation scale, enterprise transformation, and the broader trajectory toward more autonomous and generalized intelligence systems.
1. Intelligence vs Execution
Detailed Description
OpenAI has historically focused on creating systems that can reason, generate, understand, and learn across domains. This includes language, multimodal perception, reasoning chains, and alignment. OpenClaw focused on turning intelligence into real-world autonomous action. Execution involves planning, tool use, persistence, and interacting with software environments over time.
In modern AI architecture, intelligence without execution is insight without impact. Execution without intelligence is automation without adaptability. The convergence attempts to unify both.
Examples
Example 1: An OpenAI model generates a strategic business plan. An OpenClaw agent executes it by scheduling meetings, compiling market data, running simulations, and adjusting timelines autonomously.
Example 2: An enterprise AI assistant understands a complex customer service scenario. An agent system executes resolution workflows across CRM, billing, and operations platforms without human intervention.
Contribution to the Broader Discussion
This section explains why convergence matters structurally. True intelligent systems require the ability to act, not just think. This directly links to the broader conversation around autonomous systems and long-horizon intelligence, foundational components on the path toward AGI-like capabilities.
2. Model vs Agent Architecture
Detailed Description
Foundation models are probabilistic reasoning engines trained on massive datasets. Agent architectures layer on top of models and provide memory, planning, orchestration, and execution loops. Models generate intelligence. Agents operationalize intelligence over time.
Agent architecture introduces persistence, goal tracking, multi-step reasoning, and feedback loops, making systems behave more like ongoing processes rather than single interactions.
Examples
Example 1: A model answers a question about supply chain risk. An agent monitors supply chain data continuously, predicts disruptions, and autonomously reroutes logistics.
Example 2: A model writes software code. An agent iteratively builds, tests, deploys, monitors, and improves that software over weeks or months.
Contribution to the Broader Discussion
This highlights the shift from static AI to dynamic AI systems. The rise of agent architecture is central to understanding how AI moves from tool to autonomous digital operator, a key theme in consolidation and platform convergence.
3. Research vs Applied Autonomy
Detailed Description
OpenAI has historically invested in long-term AGI research, safety, and foundational intelligence. OpenClaw focused on immediate real-world deployment of autonomous agents. One prioritizes theoretical progress and safe scaling. The other prioritizes operational capability.
This duality reflects a broader industry divide between long-term intelligence and near-term automation.
Examples
Example 1: A research organization develops a reasoning model capable of complex decision making. An applied agent system deploys it to autonomously manage enterprise workflows.
Example 2: Advanced reinforcement learning research improves long-horizon reasoning. Autonomous agents use that capability to continuously optimize business operations.
Contribution to the Broader Discussion
This section explains how merging research and deployment accelerates AI progress. The faster research can be translated into real-world execution, the faster AI systems evolve, increasing both opportunity and risk.
4. Platform vs Framework
Detailed Description
OpenAI operates as a vertically integrated AI platform covering models, infrastructure, and ecosystem. OpenClaw functioned as a flexible agent framework that could operate across different model environments. Platforms centralize capability. Frameworks enable flexibility.
The strategic tension is between ecosystem control and ecosystem openness.
Examples
Example 1: A centralized AI platform offers enterprise-grade agent automation tightly integrated with its model ecosystem. A framework allows developers to deploy agents across multiple model providers.
Example 2: A platform controls identity, execution, and data pipelines. A framework allows decentralized innovation and modular agent architectures.
Contribution to the Broader Discussion
This section connects directly to consolidation risk and ecosystem dynamics. It frames how platform convergence can accelerate progress while also centralizing control over the future cognitive infrastructure.
5. Strategic Benefits of Alignment
Detailed Description
Combining advanced intelligence with autonomous execution creates a full cognitive stack capable of reasoning, planning, acting, and adapting. This reduces friction between thinking and doing, which is essential for scaling autonomous systems.
Examples
Example 1: A persistent AI system manages an enterprise transformation program end to end, analyzing data, coordinating stakeholders, and adapting execution dynamically.
Example 2: A network of autonomous agents runs digital operations, handling customer service, financial forecasting, and product optimization continuously.
Contribution to the Broader Discussion
This explains why such alignment accelerates AI capability. It strengthens the architecture required for large-scale automation and potentially for broader intelligence systems.
6. Strategic Risks and Detriments
Detailed Description
Consolidation can centralize power, expand autonomy risk, reduce competitive diversity, and increase systemic vulnerability. Autonomous systems interacting across platforms create complex adaptive behavior that becomes harder to predict or control.
Examples
Example 1: A highly autonomous agent system misinterprets objectives and executes actions that disrupt business operations at scale.
Example 2: Centralized control over agent ecosystems leads to reduced competition and increased dependence on a single platform.
Contribution to the Broader Discussion
This section introduces balance. It reframes the discussion from purely technological progress to systemic risk, governance, and long-term sustainability of AI ecosystems.
7. Practitioner Implications
Detailed Description
AI professionals must transition from focusing only on models to designing autonomous systems. This includes agent orchestration, security, alignment, and multi-agent coordination. The frontier skill set is shifting toward system architecture and platform strategy.
Examples
Example 1: An AI architect designs a secure multi-agent workflow for enterprise operations rather than building a single predictive model.
Example 2: A practitioner implements governance, monitoring, and safety layers for autonomous agent execution.
Contribution to the Broader Discussion
This connects the macro trend to individual relevance. It shows how consolidation and agent convergence reshape the AI profession and required competencies.
8. Public Understanding and Societal Implications
Detailed Description
The public must understand that AI is transitioning from passive tool to autonomous actor. The implications are economic, governance-driven, and systemic. The most immediate impact is automation and decision augmentation at scale rather than full AGI.
Examples
Example 1: Autonomous digital agents manage personal and professional workflows continuously.
Example 2: Enterprise operations shift toward AI-driven orchestration, changing workforce structures and productivity models.
Contribution to the Broader Discussion
This grounds the technical discussion in societal reality. It reframes AI progress as infrastructure transformation rather than speculative intelligence alone.
9. Strategic Focus as Consolidation Increases
Detailed Description
As consolidation continues, attention must shift toward governance, safety, interoperability, and ecosystem balance. The key challenge becomes managing powerful autonomous systems responsibly while preserving innovation.
Examples
Example 1: Developing transparent reasoning systems that allow oversight into autonomous decisions.
Example 2: Maintaining hybrid ecosystems where open-source and centralized platforms coexist.
Contribution to the Broader Discussion
This section connects the entire narrative. It frames consolidation not as an isolated event but as part of a long-term structural shift toward autonomous cognitive infrastructure.
Closing Strategic Synthesis
The convergence of intelligence and autonomous execution represents a transition from AI as a computational tool to AI as an operational system. This shift strengthens the structural foundation required for higher-order intelligence while simultaneously introducing new systemic risks.
The broader discussion is not simply about one partnership or consolidation event. It is about the emergence of persistent autonomous systems embedded across economic, technological, and societal infrastructure. Understanding this transition is essential for practitioners, policymakers, and the public as AI moves toward deeper integration into real-world systems.
Please follow us on (Spotify) as we discuss this and many other similar topics.
A Structural Inflection or a Temporary Constraint?
There is a consumer versus producer mentality that currently exists in the world of artificial intelligence. The consumer of AI wants answers, advice and consultation quickly and accurately but with minimal “costs” involved. The producer wants to provide those results, but also realizes that there are “costs” to achieve this goal. Is there a way to satisfy both, especially when expectations on each side are excessive? Additionally, is there a way to balance both without a negative hit to innovation?
Artificial intelligence has transitioned from experimental research to critical infrastructure. Large-scale models now influence healthcare, science, finance, defense, and everyday productivity. Yet the physical backbone of AI, hyperscale data centers, consumes extraordinary amounts of electricity, water, land, and rare materials. Lawmakers in multiple jurisdictions have begun proposing pauses or stricter controls on new data center construction, citing grid strain, environmental concerns, and long-term sustainability risks.
The central question is not whether AI delivers value. It clearly does. The real debate is whether the marginal cost of continued scaling is beginning to exceed the marginal benefit. This post examines both sides, evaluates policy and technical options, and provides a structured framework for decision making.
The Case That AI Costs Are Becoming Unsustainable
1. Resource Intensity and Infrastructure Strain
Training frontier AI models requires vast electricity consumption, sometimes comparable to small cities. Data centers also demand continuous cooling, often using significant freshwater resources. Land use for hyperscale campuses competes with residential, agricultural, and ecological priorities.
Core Concern: AI scaling may externalize environmental and infrastructure costs to society while benefits concentrate among technology leaders.
Implications
Grid instability and rising electricity prices in certain regions
Water stress in drought-prone geographies
Increased carbon emissions if powered by non-renewable energy
2. Diminishing Returns From Scaling
Recent research indicates that simply increasing compute does not always yield proportional gains in intelligence or usefulness. The industry may be approaching a point where costs grow exponentially while performance improves incrementally.
Core Concern: If innovation slows relative to cost, continued large-scale expansion may be economically inefficient.
3. Policy Momentum and Public Pressure
Some lawmakers have proposed temporary pauses on new data center construction until infrastructure and environmental impact are better understood. These proposals reflect growing public concern over energy use, water consumption, and long-term sustainability.
Core Concern: Unregulated expansion could lead to regulatory backlash or abrupt constraints that disrupt innovation ecosystems.
The Case That AI Benefits Still Outweigh the Costs
1. AI as Foundational Infrastructure
AI is increasingly comparable to electricity or the internet. Its downstream value in productivity, medical discovery, automation, and scientific progress may dwarf the resource cost required to sustain it.
Examples
Drug discovery acceleration reducing R&D timelines dramatically
AI-driven diagnostics improving early detection of disease
Industrial optimization lowering global energy consumption
Argument: Short-term resource cost may enable long-term systemic efficiency gains across the entire economy.
2. Innovation Drives Efficiency
Historically, technological scaling produces optimization. Early data centers were inefficient, yet modern hyperscale facilities use advanced cooling, renewable energy, and optimized chips that dramatically reduce energy per computation.
Argument: The industry is still early in the efficiency curve. Costs today may fall significantly over the next decade.
3. Strategic and Economic Competitiveness
AI leadership has geopolitical and economic implications. Restricting development could slow innovation domestically while other regions accelerate, shifting technological power and economic advantage.
Below are structured approaches that policymakers and industry leaders could consider.
Option 1: Temporary Pause on Data Center Expansion
Description: Halt new large-scale AI infrastructure until environmental and grid impact assessments are completed.
Pros
Prevents uncontrolled environmental impact
Allows infrastructure planning and regulation to catch up
Encourages efficiency innovation instead of brute-force scaling
Cons
Slows AI progress and research momentum
Risks economic and geopolitical disadvantage
Could increase costs if supply of compute becomes constrained
Example: A region experiencing power shortages pauses data center growth to avoid grid failure but delays major AI research investments.
Option 2: Regulated Expansion With Sustainability Mandates
Description: Continue building data centers but require strict sustainability standards such as renewable energy usage, water recycling, and efficiency targets.
Pros
Maintains innovation trajectory
Forces environmental responsibility
Encourages investment in green energy and cooling technology
Cons
Increases upfront cost for operators
May slow deployment due to compliance complexity
Could concentrate AI infrastructure among large players able to absorb costs
Example: A hyperscale facility must run primarily on renewable power and use closed-loop water cooling systems.
Description: Prioritize algorithmic efficiency, smaller models, and edge AI instead of increasing data center size.
Pros
Reduces resource consumption
Encourages breakthrough innovation in model architecture
Makes AI more accessible and decentralized
Cons
May slow progress toward advanced general intelligence
Requires fundamental research breakthroughs
Not all workloads can be efficiently miniaturized
Example: Transition from trillion-parameter brute-force models to smaller, optimized models delivering similar performance.
Option 4: Distributed and Regionalized AI Infrastructure
Description: Spread smaller, efficient data centers geographically to balance resource demand and grid load.
Pros
Reduces localized strain on infrastructure
Improves resilience and redundancy
Enables regional energy optimization
Cons
Increased coordination complexity
Potentially higher operational overhead
Network latency and data transfer challenges
Critical Evaluation: Which Direction Makes the Most Sense?
From a systems perspective, a full pause is unlikely to be optimal. AI is becoming core infrastructure, and abrupt restriction risks long-term innovation and economic consequences. However, unconstrained expansion is also unsustainable.
Most viable strategic direction: A hybrid model combining regulated expansion, efficiency innovation, and infrastructure modernization.
Key Questions for Decision Makers
Readers should consider:
Are we measuring AI cost only in energy, or also in societal transformation?
Would slowing AI progress reduce long-term sustainability gains from AI-driven optimization?
Is the real issue scale itself, or inefficient scaling?
Should AI infrastructure be treated like a regulated utility rather than a free-market build-out?
Forward-Looking Recommendations
Recommendation 1: Treat AI Infrastructure as Strategic Utility
Governments and industry should co-invest in sustainable energy and grid capacity aligned with AI growth.
Pros
Long-term stability
Enables controlled scaling
Aligns national strategy
Cons
High public investment required
Risk of bureaucratic slowdown
Recommendation 2: Incentivize Efficiency Over Scale
Reward innovation in energy-efficient chips, cooling, and model design.
Pros
Reduces environmental footprint
Encourages technological breakthroughs
Cons
May slow short-term capability growth
Recommendation 3: Transparent Resource Accounting
Require disclosure of energy, water, and carbon footprint of AI systems.
Pros
Enables informed policy and public trust
Drives industry accountability
Cons
Adds reporting overhead
May expose competitive information
Recommendation 4: Develop Next-Generation Sustainable Data Centers
Focus on modular, water-neutral, renewable-powered infrastructure.
Pros
Aligns innovation with sustainability
Future-proofs AI growth
Cons
Requires long-term investment horizon
Final Perspective: Inflection Point or Evolutionary Phase?
The current moment resembles not a hard limit but a transitional phase. AI has entered physical reality where compute equals energy, land, and materials. This shift forces a maturation of strategy rather than a retreat from innovation.
The real question is not whether AI costs are too high, but whether the industry and policymakers can evolve fast enough to make intelligence sustainable. If scaling continues without efficiency, constraints will eventually dominate. If innovation shifts toward smarter, greener, and more efficient systems, AI may ultimately reduce global resource consumption rather than increase it.
The inflection point, therefore, is not about stopping AI. It is about deciding how intelligence should scale responsibly.
Please consider a listen on (Spotify) as we discuss this topic and many others.
Recently another topic has become popular in the AI space and in today’s post we will discuss what’s the buzz, why is it relevant and what you need to know to filter out the noise.
We understand that software has always been written in layers of abstraction, Assembly gave way to C, C to Python, and APIs to platforms. However, today a new layer is forming above them all: intent itself.
A human will typically describe their intent in natural language, while a large language model (LLM) generates, executes, and iterates on the code. Now we hear something new “Vibe Coding” which was popularized by Andrej Karpathy – This approach focuses on rapid, conversational prototyping rather than manual coding, treating AI as a pair programmer.
What are the key Aspects of “Intent” in Vibe Coding:
Intent as Code: The developer’s articulated, high-level intent, or “vibe,” serves as the instructions, moving from “how to build” to “what to build”.
Conversational Loop: It involves a continuous dialogue where the AI acts on user intent, and the user refines the output based on immediate visual/functional feedback.
Shift in Skillset: The critical skill moves from knowing specific programming languages to precisely communicating vision and managing the AI’s output.
“Code First, Refine Later”: Vibe coding prioritizes rapid prototyping, experimenting, and building functional prototypes quickly.
Benefits & Risks: It significantly increases productivity and lowers the barrier to entry. However, it poses risks regarding code maintainability, security, and the need for human oversight to ensure the code’s quality.
Fortunately, “Vibe coding” is not simply about using AI to write code faster; it represents a structural shift in how digital systems are conceived, built, and governed. In this emerging model, natural language becomes the primary design surface, large language models act as real-time implementation engines, and engineers, product leaders, and domain experts converge around a single question: If anyone can build, who is now responsible for what gets built? This article explores how that question is reshaping the boundaries of software engineering, product strategy, and enterprise risk in an era where the distance between an idea and a deployed system has collapsed to a conversation.
Vibe Coding is one of the fastest-moving ideas in modern software delivery because it’s less a new programming language and more a new operating mode: you express intent in natural language, an LLM generates the implementation, and you iterate primarily through prompts + runtime feedback—often faster than you can “think in syntax.”
Karpathy popularized the term in early 2025 as a kind of “give in to the vibes” approach, where you focus on outcomes and let the model do much of the code writing. Merriam-Webster frames it similarly: building apps/web pages by telling an AI what you want, without necessarily understanding every line of code it produces. Google Cloud positions it as an emerging practice that uses natural language prompts to generate functional code and lower the barrier to building software.
What follows is a foundational, but deep guide: what vibe coding is, where it’s used, who’s using it, how it works in practice, and what capabilities you need to lead in this space (especially in enterprise environments where quality, security, and governance matter).
What “vibe coding” actually is (and what it isn’t)
A practical definition
At its core, vibe coding is a prompt-first development loop:
Describe intent (feature, behavior, constraints, UX) in natural language
Generate code (scaffolds, components, tests, configs, infra) via an LLM
Run and observe (compile errors, logs, tests, UI behavior, perf)
Refine by conversation (“fix this bug,” “make it accessible,” “optimize query”)
Repeat until the result matches the “vibe” (the intended user experience)
IBM describes it as prompting AI tools to generate code rather than writing it manually, loosely defined, but consistently centered on natural language + AI-assisted creation. Cloudflare similarly frames it as an LLM-heavy way of building software, explicitly tied to the term’s 2025 origin.
The key nuance: spectrum, not a binary
In practice, “vibe coding” spans a spectrum:
LLM as typing assistant (you still design, review, and own the code)
LLM as primary implementer (you steer via prompts, tests, and outcomes)
“Code-agnostic” vibe coding (you barely read code; you judge by behavior)
That last end of the spectrum is the most controversial: when teams ship outputs they don’t fully understand. Wikipedia’s summary of the term emphasizes this “minimal code reading” interpretation (though real-world teams often adopt a more disciplined middle ground).
Leadership takeaway: in serious environments, vibe coding is best treated as an acceleration technique, not a replacement for engineering rigor.
Why vibe coding emerged now
Three forces converged:
Models got good at full-stack glue work LLMs are unusually strong at “integration code” (APIs, CRUD, UI scaffolding, config, tests, scripts) the stuff that consumes time but isn’t always intellectually novel.
Tooling moved from “completion” to “agents + context” IDEs and platforms now feed models richer context: repo structure, dependency graphs, logs, test output, and sometimes multi-file refactors. This makes iterative prompting far more productive than early Copilot-era autocomplete.
Economics of prototyping changed If you can get to a working prototype in hours (not weeks), more roles participate: PMs, designers, analysts, operators or anyone close to the business problem.
Microsoft’s reporting explicitly frames vibe coding as expanding “who can build apps” and speeding innovation for both novices and pros.
Where vibe coding is being used (patterns you can recognize)
1) “Software for one” and micro-automation
Individuals build personal tools: summarizers, trackers, small utilities, workflow automations. The Kevin Roose “not a coder” narrative became a mainstream example of the phenomenon.
Enterprise analog: internal “micro-tools” that never justified a full dev cycle, until now. Think:
QA dashboard for a call center migration
Ops console for exception handling
Automated audit evidence pack generator
2) Product prototyping and UX experiments
Teams generate:
clickable UI prototypes (React/Next.js)
lightweight APIs (FastAPI/Express)
synthetic datasets for demo flows
instrumentation and analytics hooks
The value isn’t just speed, it’s optionality: you can explore 5 approaches quickly, then harden the best.
3) Startup formation and “AI-native” product development
Vibe coding has become a go-to motion for early-stage teams: prototype → iterate → validate → raise → harden later. Recent funding and “vibe coding platforms” underscore market pull for faster app creation, especially among non-traditional builders.
4) Non-engineer product building (PMs, designers, operators)
A particularly important shift is role collapse: people traditionally upstream of engineering can now implement slices of product. A recent example profiled a Meta PM describing vibe coding as “superpowers,” using tools like Cursor plus frontier models to build and iterate.
Enterprise implication: your highest-leverage builders may soon be domain experts who can also ship (with guardrails).
Who is using vibe coding (and why)
You’ll see four archetypes:
Senior engineers: use vibe coding to compress grunt work (scaffolding, refactors, test generation), so they can spend time on architecture and risk.
Founders and product teams: build prototypes to validate demand; reduce dependency bottlenecks.
Domain experts (CX ops, finance, compliance, marketing ops): build tools closest to the workflow pain.
New entrants: use vibe coding as an on-ramp, sometimes dangerously, because it can “feel” like competence before fundamentals are solid.
This is why some engineering leaders push back on the term: the risk isn’t that AI writes code; it’s that teams treat working output as proof of correctness. Recent commentary from industry leaders highlights this tension between speed and discipline.
How vibe coding is actually done (a disciplined workflow)
If you want results that scale beyond demos, the winning pattern is:
Step 1: Write a “north star” spec (before code)
A lightweight spec dramatically improves outcomes:
user story + non-goals
data model (entities, IDs, lifecycle)
APIs (inputs/outputs, error semantics)
UX constraints (latency, accessibility, devices)
security constraints (authZ, PII handling)
Prompt template (conceptual):
“Here is the spec. Propose architecture and data model. List risks. Then generate an implementation plan with milestones and tests.”
Step 2: Generate scaffolding + tests early
Ask the model to produce:
project skeleton
core domain types
happy-path tests
basic observability (logging, tracing hooks)
This anchors the build around verifiable behavior (not vibes).
Step 3: Iterate via “tight loops”
Run tests, capture stack traces, paste logs back, request fixes. This is where vibe coding shines: high-frequency micro-iterations.
IP/data risk: sensitive data in prompts, unclear training/exfil pathways
This is why mainstream commentary stresses: you still need expertise even if you “don’t need code” in the traditional sense.
What skill sets are required to be a leader in vibe coding
If you want to lead (not just dabble), the skill stack looks like this:
1) Product and problem framing (non-negotiable)
In a vibe coding environment, product and problem framing becomes the primary act of engineering.
translating ambiguous needs into specs
defining success metrics and failure modes
designing experiments and iteration loops
When implementation can be generated in minutes, the true bottleneck shifts upstream to how well the problem is defined. Ambiguity is no longer absorbed by weeks of design reviews and iterative hand-coding; it is amplified by the model and reflected back as brittle logic, misaligned features, or superficially “working” systems that fail under real-world conditions.
Leaders in this space must therefore develop the discipline to express intent with the same rigor traditionally reserved for architecture diagrams and interface contracts. This means articulating not just what the system should do, but what it must never do, defining non-goals, edge cases, regulatory boundaries, and operational constraints as first-class inputs to the build process. In practice, a well-framed problem statement becomes a control surface for the AI itself, shaping how it interprets user needs, selects design patterns, and resolves trade-offs between performance, usability, and risk.
At the organizational level, strong framing capability also determines whether vibe coding becomes a strategic advantage or a source of systemic noise. Teams that treat prompts as casual instructions often end up with fragmented solutions optimized for local convenience rather than enterprise coherence. By contrast, mature organizations codify framing into lightweight but enforceable artifacts: outcome-driven user stories, domain models that define shared language, success metrics tied to business KPIs, and explicit failure modes that describe how the system should degrade under stress. These artifacts serve as both a governance layer and a collaboration bridge, enabling product leaders, engineers, security teams, and operators to align around a single “definition of done” before any code is generated. In this model, the leader’s role evolves from feature prioritizer to systems curator—ensuring that every AI-assisted build reinforces architectural integrity, regulatory compliance, and long-term platform strategy, rather than simply accelerating short-term delivery.
Vibe coding rewards the person who can define “good” precisely.
policy for acceptable use (data, IP, regulated workflows)
code ownership and review rules
auditability and traceability for changes
What education helps most
You don’t need a PhD, but leaders typically benefit from:
CS fundamentals: data structures, networking basics, databases
Software architecture: modularity, distributed systems concepts
Security fundamentals: OWASP Top 10, authN/authZ, secrets
Cloud and DevOps: CI/CD, containers, observability
AI fundamentals: how LLMs behave, evaluation and limitations
For non-traditional builders, a practical pathway is:
learn to write specs
learn to test
learn to debug
learn to secure …then vibe code everything else.
Where this goes next (near / mid / long term)
Near term: vibe coding becomes normal for prototyping and internal tools; engineering teams formalize guardrails.
Mid term: more “full lifecycle” platforms emerge—generate, deploy, monitor, iterate—especially for SMB and departmental apps.
Long term: roles continue blending: “product builder” becomes a common expectation, while deep engineers focus on platform reliability, security, and complex systems.
Bottom line
Vibe coding is best understood as a new interface to software creation—English (and intent) becomes the primary input, while code becomes an intermediate artifact that still must be validated. The teams that win will treat vibe coding as a force multiplier paired with verification, security, and architecture discipline—not as a shortcut around them.
Please follow us on (Spotify) as we dive deeper into this topics and others.
It seems every day an article is published (most likely from the internal marketing teams) of how one AI model, application, solution or equivalent does something better than the other. We’ve all heard from OpenAI, Grok that they do “x” better than Perplexity, Claude or Gemini and vice versa. This has been going on for years and gets confusing to the casual users.
But what would happen if we asked them all to work together and use their best capabilities to create and run a business autonomously? Yes, there may be “some” human intervention involved, but is it too far fetched to assume if you linked them together they would eventually identify their own strengths and weaknesses, and call upon each other to create the ideal business? In today’s post we explore that scenario and hope it raises some questions, fosters ideas and perhaps addresses any concerns.
From Digital Assistants to Digital Executives
For the past decade, enterprises have deployed AI as a layer of optimization – chatbots for customer service, forecasting models for supply chains, and analytics engines for marketing attribution. The next inflection point is structural, not incremental: organizations architected from inception around a federation of large language models (LLMs) operating as semi-autonomous business functions.
This thought experiment explores a hypothetical venture – Helios Renewables Exchange (HRE) a digitally native marketplace designed to resurrect a concept that historically struggled due to fragmented data, capital inefficiencies, and regulatory complexity: peer-to-peer energy trading for distributed renewable producers (residential solar, micro-grids, and community wind).
The premise is not that “AI replaces humans,” but that a coalition of specialized AI systems operates as the enterprise nervous system, coordinating finance, legal, research, marketing, development, and logistics with human governance at the board and risk level. Each model contributes distinct cognitive strengths, forming an AI operating model that looks less like an IT stack and more like an executive team.
Why This Business Could Not Exist Before—and Why It Can Now
The Historical Failure Mode
Peer-to-peer renewable energy exchanges have failed repeatedly for three reasons:
Regulatory Complexity – Energy markets are governed at federal, state, and municipal levels, creating a constantly shifting legal landscape. With every election cycle the playground shifts and creates another set of obstacles.
Capital Inefficiency – Matching micro-producers and buyers at scale requires real-time pricing, settlement, and risk modeling beyond the reach of early-stage firms. Supply / Demand and the ever changing landscape of what is in-favor, and what is not has driven this.
Information Asymmetry – Consumers lack trust and transparency into energy provenance, pricing fairness, and grid impact. The consumer sees energy as a need, or right with limited options and therefore is already entering the conversation with a negative perception.
The AI Inflection Point
Modern LLMs and agentic systems enable:
Continuous legal interpretation and compliance mapping – Always monitoring the regulations and its impact – Who has been elected and what is the potential impact of “x” on our business?
Real-time financial modeling and scenario simulation – Supply / Demand analysis (monitoring current and forecasted weather scenarios)
Transparent, explainable decision logic for pricing and sourcing – If my customers ask “Why” can we provide an trustworthy response?
Autonomous go-to-market experimentation – If X, then Y calculations, to make the best decisions for consumers and the business without a negative impact on expectations.
The result is not just a new product, but a new organizational form: a business whose core workflows are natively algorithmic, adaptive, and self-optimizing.
The Coalition Model: AI as an Executive Operating System
Rather than deploying a single “super-model,” HRE is architected as a federation of AI agents, each aligned to a business function. These agents communicate through a shared event bus, governed by policy, audit logs, and human oversight thresholds.
Each agent operates independently within its domain, but strategic decisions emerge from their collaboration, mediated by a governance layer that enforces constraints, budgets, and ethical boundaries.
Regulatory/market constraints are discovered late (after build).
Customer willingness-to-pay is inferred from proxies instead of tested.
Competitive advantage is described in words, not measured in defensibility (distribution, compliance moat, data moat, etc.).
AI approach (how it’s addressed)
You want an always-on evidence pipeline:
Signal ingestion: news, policy updates, filings, public utility commission rulings, competitor announcements, academic papers.
Synthesis with citations: cluster patterns (“which states are loosening community solar rules?”), summarize with traceable sources.
Hypothesis generation: “In these 12 regions, the legal path exists + demand signals show price sensitivity.”
Experiment design: small tests to validate demand (landing pages, simulated pricing offers, partner interviews).
Decision gating: “Do we proceed to build?” becomes a repeatable governance decision, not a founder’s intuition.
Ideal model in charge: Perplexity (Research lead)
Perplexity is positioned as a research/answer engine optimized for up-to-date web-backed outputs with citations. (You can optionally pair it with Grok for social/real-time signals; see below.)
Capital allocation: what to build vs. buy vs. partner; launch sequencing by ROI/risk.
Auditability: every pricing decision produces an explanation trace (“why this price now?”).
Ideal model in charge: OpenAI (Finance lead / reasoning + orchestration)
Reasoning-heavy models are typically the best “financial integrators” because they must reconcile competing constraints (growth vs. risk vs. compliance) and produce coherent policies that other agents can execute. (In practice you’d pair the LLM with deterministic computation—Monte Carlo, optimization solvers, accounting engines—while the model orchestrates and explains.)
Example outputs
Live 3-statement model (P&L, balance sheet, cashflow) updated from product telemetry and pipeline.
Market entry sequencing plan (e.g., launch Region A, then B) based on risk-adjusted contribution margin.
Settlement policy (e.g., T+1 vs T+3) and associated reserve requirements.
Pricing policy artifacts that Marketing can explain and Legal can defend.
How it supports other phases
Gives Marketing “price fairness narratives” and guardrails (“we don’t do surge pricing above X”).
Gives Legal a basis for disclosures and consumer protection compliance.
Gives Development non-negotiable platform requirements (ledger, reconciliation, controls).
Gives Ops real-time constraints on capacity, downtime penalties, and service levels.
Phase 3 – Brand, Trust, and Demand Generation (Trust is the Product)
The issue
In regulated marketplaces, customers don’t buy “features”; they buy trust:
“Is this legal where I live?”
“Is the price fair and stable?”
“Will the utility punish me or block me?”
“Do I understand what I’m signing up for?”
If Marketing is disconnected from Legal/Finance, you get:
Ideal model in charge: Claude (Marketing lead / long-form narrative + policy-aware tone)
Claude is often used for high-quality long-form writing and structured communication, and its ecosystem emphasizes tool use for more controlled workflows. That makes it a strong “Chief Growth Agent” where brand voice + compliance alignment matters.
Example outputs
Compliance-safe messaging matrix: what can be said to whom, where, with what disclosures.
Onboarding explainer flows that adapt to region (legal terms, settlement timing, pricing).
Experiment playbooks: what we test, success thresholds, and when to stop.
Trust dashboard: comprehension score, complaint risk predictors, churn leading indicators.
How it supports other phases
Feeds Sales with validated value propositions and objection handling grounded in evidence.
Feeds Finance with CAC/LTV reality and forecast impacts.
Feeds Legal by surfacing “claims pressure” early (before it becomes a regulatory issue).
Feeds Product/Dev with friction points and feature priorities based on real behavior.
Phase 4 – Platform Development (Policy-Aware Product Engineering)
The issue
Traditional product builds assume stable rules. Here, rules change:
Geographic compliance differences
Data privacy and consent requirements
Utility integration differences
Settlement and billing requirements
If you build first and compliance later, you create a rewrite trap.
AI approach
Build “compliance and explainability” as platform primitives:
Ideal model in charge: Gemini (Development lead / multimodal + long context)
Gemini is positioned strongly for multimodal understanding and long-context work—useful when engineering requires digesting large specs, contracts, and integration docs across partners.
Example outputs
Policy-aware transaction pipeline: rejects/flags invalid trades by jurisdiction.
Explainability layer: “why was this trade priced/approved/denied?”
Integration adapters: utilities, IoT meter providers, payment rails.
Marketplaces need both sides. Early-stage failure modes:
You acquire consumers but not producers (or vice versa).
Partnerships take too long; pilots stall.
Deal terms are inconsistent; delivery breaks.
Sales says “yes,” Ops says “we can’t.”
AI approach
Turn sales into an integrated system:
Account intelligence: identify likely partners (utilities, installers, community solar groups).
Qualification: quantify fit based on region, readiness, compliance complexity, economics.
Proposal generation: create terms aligned to product realities and legal constraints.
Negotiation assistance: playbook-based objection handling and concession strategy.
Liquidity engineering: ensure both sides scale in tandem via targeted offers.
Ideal model in charge: OpenAI (Sales lead / negotiation + multi-party reasoning)
Sales is cross-functional reasoning: pricing (Finance), promises (Legal), delivery (Ops), features (Dev). A strong general reasoning/orchestration model is ideal here.
Post-incident learning: generate root cause analysis and prevention improvements.
Ideal model in charge: Grok (Ops lead / real-time context)
Grok is positioned around real-time access (including public X and web search) and “up-to-date” responses. That bias toward real-time context makes it a credible “ops intelligence” lead—particularly for external signal detection (outages, regional events, public reports). Important note: recent news highlights safety controversies around Grok’s image features, so in a real design you’d tightly sandbox capabilities and restrict sensitive tool access.
Fraud containment playbooks: stepwise actions with audit trails.
Capacity and reliability forecasts for Finance and Sales.
How it supports other phases
Protects Brand/Marketing by preventing trust erosion and enabling transparent comms.
Protects Finance by avoiding leakage (fraud, bad settlement, churn).
Protects Legal by producing regulator-grade logs and consistent process adherence.
Informs Development where to harden the platform next.
The Collaboration Layer (What Makes the Phases Work Together)
To make this feel like a real autonomous enterprise (not a set of siloed bots), you need three cross-cutting systems:
Shared “Truth” Substrate
An immutable ledger of transactions + decisions + rationales (who/what/why).
A single taxonomy for markets, products, customer segments, risk, and compliance.
Policy & Permissioning
Tool access controls by phase (e.g., Ops can pause settlement; Marketing cannot).
Hard constraints (budget limits, pricing limits, approved claim language).
Decision Gates
Explicit thresholds where the system must escalate to human governance:
Market entry
Major pricing policy changes
Material compliance changes
Large capital commitments
Incident severity beyond defined bounds
Governance: The Human Layer That Still Matters
This business is not “run by AI alone.” Humans occupy:
Board-level strategy
Ethical oversight
Regulatory accountability
Capital allocation authority
Their role shifts from operational decision-making to system design and governance:
Setting policy constraints
Defining acceptable risk
Auditing AI decision logs
Intervening in edge cases
The enterprise becomes a cybernetic system, AI handles execution, humans define purpose.
Strategic Implications for Practitioners
For CX, digital, and transformation leaders, this model introduces new design principles:
Experience Is a System Property Customer trust emerges from how finance, legal, and operations interact, not just front-end design. (Explainable and Transparent)
Determinism and Transparency Become Competitive Advantages Explainable AI decisions in pricing, compliance, and sourcing differentiate the brand. (Ambiguity is a negative)
Operating Models Replace Tech Stacks Success depends less on which model you use and more on how you orchestrate them. Get the strategic processes stabilized and the the technology will follow.
Governance Is the New Innovation Bottleneck The fastest businesses will be those that design ethical and regulatory frameworks that scale as fast as their AI agents.
The End State: A Business That Never Sleeps
Helios Renewables Exchange is not a company in the traditional sense—it is a living system:
Always researching
Always optimizing
Always negotiating
Always complying
The frontier is not autonomy for its own sake. It is organizational intelligence at scale—enterprises that can sense, decide, and adapt faster than any human-only structure ever could.
For leaders, the question is no longer:
“How do we use AI in our business?”
It is:
“How do we design a business that is, at its core, an AI-native system?”
Conclusion:
At a technical and organizational level, linking multiple AI models into a federated operating system is a realistic and increasingly viable approach to building a highly autonomous business, but not a fully independent one. The core feasibility lies in specialization and orchestration: different models can excel at research, reasoning, narrative, multimodal engineering, real-time operations, and compliance, while a shared policy layer and event-driven architecture allows them to coordinate as a coherent enterprise. In this construct, autonomy is not defined by the absence of humans, but by the system’s ability to continuously sense, decide, and act across finance, product, legal, and go-to-market workflows without manual intervention. The practical boundary is no longer technical capability; it is governance, specifically how risk thresholds, capital constraints, regulatory obligations, and ethical policies are codified into machine-enforceable rules.
However, the conclusion for practitioners and executives is that “extremely limited human oversight” is only sustainable when humans shift from operators to system architects and fiduciaries. AI coalitions can run day-to-day execution, optimization, and even negotiation at scale, but they cannot own accountability in the legal, financial, and societal sense. The realistic end state is a cybernetic enterprise: one where AI handles speed, complexity, and coordination, while humans retain authority over purpose, risk appetite, compliance posture, and strategic direction. In this model, autonomy becomes a competitive advantage not because the business is human-free, but because it is governed by design rather than managed by exception, allowing organizations to move faster, more transparently, and with greater structural resilience than traditional operating models.
Please follow us on (Spotify) as we discuss this and other topics more in depth.
Today’s discussion revolves around “Human emulation” which has become a hot topic because it reframes AI from content generation to capability replication: systems that can reliably do what humans do, digitally (knowledge work) and physically (manual work), with enough autonomy to run while people sleep.
Autonomous digital workers (agentic AI that can operate tools, applications, and workflows end-to-end).
Autonomous mobile assets (cars that can generate revenue when the owner isn’t using them).
Autonomous physical workers (humanoids that can perform tasks in human-built environments).
Tesla is clearly driving (2) and (3). xAI is positioning itself as a serious contender for (1) and likely as the “brain layer” that connects these domains.
Tesla’s Human Emulation Stack: Car-as-Worker and Robot-as-Worker
1) “Earn while you sleep”: the autonomous vehicle as an income-producing asset
The most concrete “human emulation” narrative from Tesla is the claim that a Tesla could join a robotaxi network to generate revenue when idle, conceptually similar to Airbnb for cars. Tesla has publicly promoted the idea that a vehicle could “earn money while you’re not using it.”
On the operational side, Tesla has been running a limited robotaxi service (not yet the “no-supervision everywhere” end state). Reporting in 2025 noted Tesla’s robotaxi approach is expanding gradually and still uses safety monitoring in some form, underscoring that this is a staged rollout rather than a flip-the-switch moment.
Why this matters for “human emulation”: A human rideshare driver monetizes time. A robotaxi monetizes asset uptime. If Tesla achieves high autonomy + acceptable insurance/regulatory frameworks + scalable operations (charging, cleaning, dispatch), then the “sleeping hours” of the owner become economically productive.
Practitioner lens: expect the first big enterprise opportunities not in consumer “passive income,” but in fleet economics (airports, hotels, logistics, managed mobility) where charging/cleaning/maintenance can be industrialized.
2) Optimus: emulating physical labor (not just movement)
Tesla’s own positioning for Optimus is explicit: a general-purpose bipedal humanoid intended for “unsafe, repetitive or boring tasks.”
Independent reporting continues to emphasize two realities at once:
Tesla is serious about scaling Optimus and tying it to the autonomy stack.
The industry is split on humanoid form factors; many experts argue task-specific robots outperform humanoids for most industrial work—at least for the foreseeable future.
Why this matters for “human emulation”: The humanoid bet isn’t about novelty, it’s about compatibility with human environments (stairs, doors, tools, workstations) and the option value of “one robot, many tasks,” even if early deployments are narrow.
3) Compute is the flywheel: chips + training infrastructure
If you assume autonomy and robotics are compute-hungry, then Tesla’s investments in AI compute and custom silicon become part of the “human emulation” story. Recent reporting highlighted Tesla’s continued push toward in-house compute/AI hardware ambitions (e.g., Dojo-related efforts and new chip roadmaps).
Why this matters: Human emulation at scale is less about one model and more about a factory of models: perception, planning, manipulation, dialogue, compliance, simulation, and continuous learning loops.
xAI’s Role: Digital Human Emulation (Agentic Work), Not Just Chat
1) Grok’s shift from “chatbot” to “agent”
xAI has been pushing into agentic capabilities, not just answering questions, but executing tasks via tools. In late 2025, xAI announced an Agent Tools API positioned explicitly to let Grok operate as an autonomous agent.
This matters because “digital human emulation” is often less about deep reasoning and more about:
navigating enterprise systems,
orchestrating multi-step workflows,
using tools correctly,
handling exceptions,
producing auditable outcomes.
That is the core of how you replace “a person at a keyboard” with “a system at a keyboard.”
2) What xAI may be building beyond “let your Tesla do side jobs”
You asked to explore what xAI might be doing beyond leveraging Teslas for secondary jobs. Here are the plausible directions—grounded in what xAI has publicly disclosed (agent tooling) and what the market is converging on (agents as workflow executors), while being clear about where we’re extrapolating.
A) “Digital workers” that emulate office roles (high-likelihood near/mid-term)
Given xAI’s tooling direction, the near-term “human emulation” play is enterprise-grade agents that can:
execute customer operations tasks,
do research + analysis with sources,
create and update tickets, CRM objects, and knowledge articles,
coordinate with human approvers.
This aligns with the general definition of AI agents as systems that autonomously perform tasks on behalf of users.
What would differentiate xAI here? Potentially:
tight integration with real-time public data streams (notably X, where available),
B) “Embodied digital humans” for customer-facing interactions (mid-term)
There’s a parallel trend toward digital humans and embodied agents, lifelike interfaces that feel more human in conversation. If xAI pairs high-function agents with high-presence interfaces, you get customer experiences that look and feel like “talking to a person,” while being backed by robust tool execution.
For CX leaders, the key shift is: the interface becomes humanlike, but the value is in the agent’s ability to do things, not just talk.
C) A cross-company autonomy layer (long-term, speculative but coherent)
The most ambitious “Musk ecosystem” interpretation is an autonomy platform spanning:
digital work (xAI agents),
mobility work (Tesla robotaxi),
physical work (Optimus).
That would create an internal advantage: shared training approaches, shared safety tooling, shared simulation, and (critically) shared distribution.
Nothing public proves a unified roadmap across all entities—so treat this as a strategic pattern rather than a confirmed plan. What is public is Tesla’s emphasis on autonomy/robotics scale and xAI’s emphasis on agentic execution.
Near-, Mid-, and Long-Term Vision (A Practitioner’s Map)
Near term (0–24 months): “Humans-in-the-loop at scale”
What you’ll likely see:
Agentic systems that complete tasks but still require approvals for sensitive actions (refunds, cancellations, policy exceptions).
Robotaxi expansion remains geographically constrained and operationally monitored in meaningful ways (safety, regulation, insurance).
Early Optimus deployments remain limited, structured, and heavily operationalized.
Winning moves for practitioners:
Build workflow-native agent deployments (CRM, ITSM, ERP), not “chat next to the workflow.”
Invest in process instrumentation (event logs, exception taxonomies, policy rules) so agents can act safely.
Digital labor begins to reshape operating models: fewer handoffs, more straight-through processing.
In mobility, if Tesla’s robotaxi scales, ecosystems emerge for fleet ops (cleaning, charging, remote assist, insurance products, municipal partnerships).
Winning moves for practitioners:
Treat agents as a new workforce category: onboarding, role design, permissions, QA, drift monitoring, and continuous improvement.
Implement policy-as-code for agent actions (what it may do, with what evidence, with what approvals).
Modernize your knowledge architecture: retrieval is necessary but insufficient—agents need transactional authority with guardrails.
Long term (5–10+ years): “Economic structure changes around machine labor”
What you’ll likely see:
A meaningful portion of “routine knowledge work” becomes machine-executed.
Physical automation (humanoids and non-humanoids) expands, but unevenly task suitability and ROI will dominate.
Regulatory and societal pressure increases around accountability, job transitions, and safety.
Redesign experiences assuming “the worker is software” (24/7 service, instant fulfillment) while keeping human escalation excellent.
Prepare for brand risk: “human emulation” failures are reputationally louder than ordinary software bugs.
Societal Impact: The Second-Order Effects Leaders Underestimate
Labor shifts from time to orchestration The scarce skill becomes not “doing tasks,” but designing systems that do tasks safely.
The accountability gap becomes the battleground When an agent acts, who is responsible; vendor, operator, enterprise, user? This is where governance becomes a competitive advantage.
New inequality vectors appear If asset ownership (cars, robots, compute) drives income, then autonomy can amplify returns to capital faster than returns to labor.
Customer expectations reset Once autonomous systems deliver instant, 24/7 outcomes, customers will view “business hours” and “wait 3–5 days” as broken experiences.
What a Practitioner Should Be Aware Of (and How to Get in Front)
The big risks to plan for
Operational reality risk: “autonomous” still requires edge-case handling, maintenance, and exception operations (digital and physical).
Governance risk: without tight permissions and auditability, agents create compliance exposure.
Model drift & policy drift: the system remains “correct” only if data, policies, and monitoring stay aligned.
Practical steps to get ahead (starting now)
Pick 3 workflows where a digital human already exists Meaning: a person follows a repeatable playbook across systems (refunds, order changes, ticket triage, appointment rescheduling).
Continuous evaluation (golden sets + live monitoring)
Create an autonomy roadmap with three lanes
Assistive (draft, suggest, summarize)
Transactional (execute with guardrails)
Autonomous (execute + self-correct + escalate)
For mobility/robotics: partner early, but operationalize hard If you’re exploring “vehicle-as-worker” economics, treat it like launching a micro-logistics business: charging, cleaning, incident response, insurance, and municipal constraints will dominate outcomes before the AI does.
Bottom Line
Tesla is pursuing human emulation in the physical world (Optimus) and human-emulation economics in mobility (robotaxi-as-income). xAI is laying groundwork for human emulation in digital work via agentic tooling that can execute tasks, not just respond.
If you want to get in front of this, don’t start with “Which model?” Start with: Which outcomes will you allow a machine to own end-to-end, under what controls, with what proof?
Please join us on (Spotify) as we discuss this and other topics in the AI space.
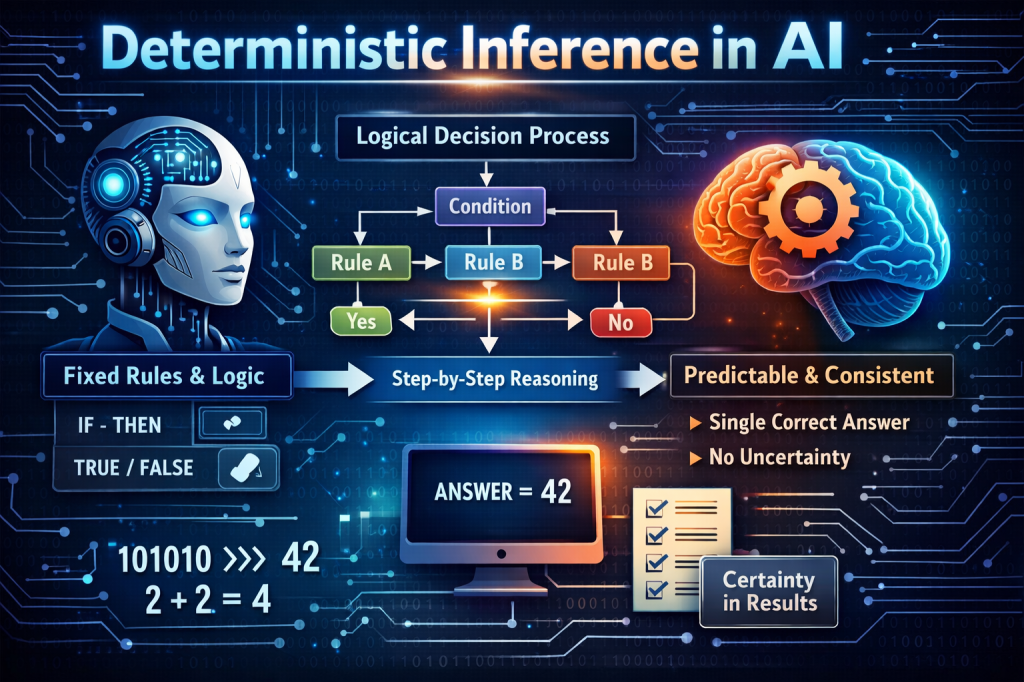
Introduction: Why Determinism Matters to Customer Experience
Customer Experience (CX) leaders increasingly rely on AI to shape how customers are served, advised, and supported. From virtual agents and recommendation engines to decision-support tools for frontline employees, AI is now embedded directly into the moments that define customer trust.
In this context, deterministic inference is not a technical curiosity, it is a CX enabler. It determines whether customers receive consistent answers, whether agents trust AI guidance, and whether organizations can scale personalized experiences without introducing confusion, risk, or inequity.
This article reframes deterministic inference through a CX lens. It begins with an intuitive explanation, then explores how determinism influences customer trust, operational consistency, and experience quality in AI-driven environments. By the end, you should be able to articulate why deterministic inference is central to modern CX strategy and how it shapes the future of AI-powered customer engagement.
Part 1: Deterministic Thinking in Everyday Customer Experiences
At a basic level, customers expect consistency.
If a customer:
Checks an order status online
Calls the contact center later
Chats with a virtual agent the next day
They expect the same answer each time.
This expectation maps directly to determinism.
A Simple CX Analogy
Consider a loyalty program:
Input: Customer ID + purchase history
Output: Loyalty tier and benefits
If the system classifies a customer as Gold on Monday and Silver on Tuesday—without any change in behavior—the experience immediately degrades. Trust erodes.
Customers may not know the word “deterministic,” but they feel its absence instantly.
Part 2: What Inference Means in CX-Oriented AI Systems
In CX, inference is the moment AI translates customer data into action.
Examples include:
Deciding which response a chatbot gives
Recommending next-best actions to an agent
Determining eligibility for refunds or credits
Personalizing offers or messaging
Inference is where customer data becomes customer experience.
Part 3: Deterministic Inference Defined for CX
From a CX perspective, deterministic inference means:
Given the same customer context, business rules, and AI model state, the system produces the same customer-facing outcome every time.
This does not mean experiences are static. It means they are predictably adaptive.
Why This Is Non-Trivial in Modern CX AI
Many CX AI systems introduce variability by design:
Generative chat responses – Replies produced by an artificial intelligence (AI) system that uses machine learning to create original, human-like text in real-time, rather than relying on predefined scripts or rules. These responses are generated based on patterns the AI has learned from being trained on vast amounts of existing data, such as books, web pages, and conversation examples.
Probabilistic intent classification – a machine learning method used in natural language processing (NLP) to identify the purpose behind a user’s input (such as a chat message or voice command) by assigning a probability distribution across a predefined set of potential goals, rather than simply selecting a single, most likely intent.
Dynamic personalization models – Refer to systems that automatically tailor digital content and user experiences in real time based on an individual’s unique preferences, past behaviors, and current context. This approach contrasts with static personalization, which relies on predefined rules and broad customer segments.
Agentic workflows – An AI-driven process where autonomous “agents” independently perform multi-step tasks, make decisions, and adapt to changing conditions to achieve a goal, requiring minimal human oversight. Unlike traditional automation that follows strict rules, agentic workflows use AI’s reasoning, planning, and tool-use abilities to handle complex, dynamic situations, making them more flexible and efficient for tasks like data analysis, customer support, or IT management.
Without guardrails, two customers with identical profiles may receive different experiences—or the same customer may receive different answers across channels.
Part 4: Deterministic vs. Probabilistic CX Experiences
The customer receives the same answer regardless of channel, agent, or time.
Part 5: Why Deterministic Inference Is Now a CX Imperative
1. Omnichannel Consistency
A customer-centric strategy that creates a seamless, integrated, and consistent brand experience across all customer touchpoints, whether online (website, app, social media, email) or offline (physical store), allowing customers to move between channels effortlessly with a unified journey. It breaks down silos between channels, using customer data to deliver personalized, real-time interactions that build loyalty and drive conversions, unlike multichannel, which often keeps channels separate.
Customers move fluidly across a marketing centered ecosystem: (Consisting typically of)
Web
Mobile
Chat
Voice
Human agents
Deterministic inference ensures that AI behaves like a single brain, not a collection of loosely coordinated tools.
2. Trust and Perceived Fairness
Trust and perceived fairness are two of the most fragile and valuable assets in customer experience. AI systems, particularly those embedded in service, billing, eligibility, and recovery workflows, directly influence whether customers believe a company is acting competently, honestly, and equitably.
Deterministic inference plays a central role in reinforcing both.
Defining Trust and Fairness in a CX Context
Customer Trust can be defined as:
The customer’s belief that an organization will behave consistently, competently, and in the customer’s best interest across interactions.
Trust is cumulative. It is built through repeated confirmation that the organization “remembers,” “understands,” and “treats me the same way every time under the same conditions.”
Perceived Fairness refers to:
The customer’s belief that decisions are applied consistently, without arbitrariness, favoritism, or hidden bias.
Importantly, perceived fairness does not require that outcomes always favor the customer—only that outcomes are predictable, explainable, and consistently applied.
How Non-Determinism Erodes Trust
When AI-driven CX systems are non-deterministic, customers may experience:
Different answers to the same question on different days
Different outcomes depending on channel (chat vs. voice vs. agent)
Inconsistent eligibility decisions without explanation
From the customer’s perspective, this variability feels indistinguishable from:
Incompetence
Lack of coordination
Unfair treatment
Even if every response is technically “reasonable,” inconsistency signals unreliability.
Policy interpretation does not drift between interactions
AI behavior is stable over time unless explicitly changed
This creates what customers experience as institutional memory and coherence.
Customers begin to trust that:
The system knows who they are
The rules are real (not improvised)
Outcomes are not arbitrary
Trust, in this sense, is not emotional—it is structural.
Determinism as the Foundation of Perceived Fairness
Fairness in CX is primarily about consistency of application.
Deterministic inference supports fairness by:
Applying the same logic to all customers with equivalent profiles
Eliminating accidental variance introduced by sampling or generative phrasing
Enabling clear articulation of “why” a decision occurred
When determinism is present, organizations can say:
“Anyone in your situation would have received the same outcome.”
That statement is nearly impossible to defend in a non-deterministic system.
Real-World CX Examples
Example 1: Billing Disputes
A customer disputes a late fee.
Non-deterministic system:
Chatbot waives the fee
Phone agent denies the waiver
Follow-up email escalates to a partial credit
The customer concludes the process is arbitrary and learns to “channel shop.”
Deterministic system:
Eligibility rules are fixed
All channels return the same decision
Explanation is consistent
Even if the fee is not waived, the experience feels fair.
Example 2: Service Recovery Offers
Two customers experience the same outage.
Non-deterministic AI generates different goodwill offers
One customer receives a credit, the other an apology only
Perceived inequity emerges immediately—often amplified on social media.
Deterministic inference ensures:
Outage classification is stable
Compensation logic is uniformly applied
Example 3: Financial or Insurance Eligibility
In lending, insurance, or claims environments:
Customers frequently recheck decisions
Outcomes are scrutinized closely
Deterministic inference enables:
Reproducible decisions during audits
Clear explanations to customers
Reduced escalation to human review
The result is not just compliance—it is credibility.
Trust, Fairness, and Escalation Dynamics
Inconsistent AI decisions increase:
Repeat contacts
Supervisor escalations
Customer complaints
Deterministic systems reduce these behaviors by removing perceived randomness.
When customers believe outcomes are consistent and rule-based, they are less likely to challenge them—even unfavorable ones.
Key CX Takeaway
Deterministic inference does not guarantee positive outcomes for every customer.
What it guarantees is something more important:
Consistency over time
Uniform application of rules
Explainability of decisions
These are the structural prerequisites for trust and perceived fairness in AI-driven customer experience.
3. Agent Confidence and Adoption
Frontline employees quickly disengage from AI systems that contradict themselves.
Deterministic inference:
Reinforces agent trust
Reduces second-guessing
Improves adherence to AI recommendations
Part 6: CX-Focused Examples of Deterministic Inference
Example 1: Contact Center Guidance
Input: Customer tenure, sentiment, issue type
Output: Recommended resolution path
If two agents receive different guidance for the same scenario, experience variance increases.
Example 2: Virtual Assistants
A customer asks the same question on chat and voice.
Deterministic inference ensures:
Identical policy interpretation
Consistent escalation thresholds
Example 3: Personalization Engines
Determinism ensures that personalization feels intentional – not random.
Customers should recognize patterns, not unpredictability.
Part 7: Deterministic Inference and Generative AI in CX
Generative AI has fundamentally changed how organizations design and deliver customer experiences. It enables natural language, empathy, summarization, and personalization at scale. At the same time, it introduces variability that if left unmanaged can undermine consistency, trust, and operational control.
Deterministic inference is the mechanism that allows organizations to harness the strengths of generative AI without sacrificing CX reliability.
Defining the Roles: Determinism vs. Generation in CX
To understand how these work together, it is helpful to separate decision-making from expression.
Deterministic Inference (CX Context)
The process by which customer data, policy rules, and business logic are evaluated in a repeatable way to produce a fixed outcome or decision.
Examples include:
Eligibility decisions
Next-best-action selection
Escalation thresholds
Compensation logic
Generative AI (CX Context)
The process of transforming decisions or information into human-like language, tone, or format.
Examples include:
Writing a response to a customer
Summarizing a case for an agent
Rephrasing policy explanations empathetically
In mature CX architectures, generative AI should not decide what happens -only how it is communicated.
Why Unconstrained Generative AI Creates CX Risk
When generative models are allowed to perform inference implicitly, several CX risks emerge:
Policy drift: responses subtly change over time
Inconsistent commitments: different wording implies different entitlements
Hallucinated exceptions or promises
Channel-specific discrepancies
From the customer’s perspective, these failures manifest as:
“The chatbot told me something different.”
“Another agent said I was eligible.”
“Your email says one thing, but your app says another.”
None of these are technical errors—they are experience failures caused by nondeterminism.
How Deterministic Inference Stabilizes Generative CX
Deterministic inference creates a stable backbone that generative AI can safely operate on.
It ensures that:
Business decisions are made once, not reinterpreted
All channels reference the same outcome
Changes occur only when rules or models are intentionally updated
Generative AI then becomes a presentation layer, not a decision-maker.
This separation mirrors proven software principles: logic first, interface second.
Canonical CX Architecture Pattern
A common and effective pattern in production CX systems is:
This pattern allows organizations to scale generative CX safely.
Real-World CX Examples
Example 1: Policy Explanations in Contact Centers
Deterministic inference determines:
Whether a fee can be waived
The maximum allowable credit
Generative AI determines:
How the explanation is phrased
The level of empathy
Channel-appropriate tone
The outcome remains fixed; the expression varies.
Example 2: Virtual Agent Responses
A customer asks: “Can I cancel without penalty?”
Deterministic layer evaluates:
Contract terms
Timing
Customer tenure
Generative layer constructs:
A clear, empathetic explanation
Optional next steps
This prevents the model from improvising policy interpretation.
Example 3: Agent Assist and Case Summaries
In agent-assist tools:
Deterministic inference selects next-best-action
Generative AI summarizes context and rationale
Agents see consistent guidance while benefiting from flexible language.
Example 4: Service Recovery Messaging
After an outage:
Deterministic logic assigns compensation tiers
Generative AI personalizes apology messages
Customers receive equitable treatment with human-sounding communication.
Determinism, Generative AI, and Compliance
In regulated industries, this separation is critical.
Deterministic inference enables:
Auditability of decisions
Reproducibility during disputes
Clear separation of logic and language
Generative AI, when constrained, does not threaten compliance—it enhances clarity.
Part 8: Determinism in Agentic CX Systems
As customer experience platforms evolve, AI systems are no longer limited to answering questions or generating text. Increasingly, they are becoming agentic – capable of planning, deciding, acting, and iterating across multiple steps to resolve customer needs.
Agentic CX systems represent a step change in automation power. They also introduce a step change in risk.
Deterministic inference is what allows agentic CX systems to operate safely, predictably, and at scale.
Defining Agentic AI in a CX Context
Agentic AI (CX Context) refers to AI systems that can:
Decompose a customer goal into steps
Decide which actions to take
Invoke tools or workflows
Observe outcomes and adjust behavior
Examples include:
An AI agent that resolves a billing issue end-to-end
A virtual assistant that coordinates between systems (CRM, billing, logistics)
An autonomous service agent that proactively reaches out to customers
In CX, agentic systems are effectively digital employees operating customer journeys.
Why Agentic CX Amplifies the Need for Determinism
Unlike single-response AI, agentic systems:
Make multiple decisions per interaction
Influence downstream systems
Accumulate effects over time
Without determinism, small variations compound into large experience divergence.
This leads to:
Different resolution paths for identical customers
Inconsistent journey lengths
Unpredictable escalation behavior
Inability to reproduce or debug failures
In CX terms, the journey itself becomes unstable.
Deterministic Inference as Journey Control
Deterministic inference acts as a control system for agentic CX.
It ensures that:
Identical customer states produce identical action plans
Tool selection follows stable rules
State transitions are predictable
Rather than improvising journeys, agentic systems execute governed playbooks.
This transforms agentic AI from a creative actor into a reliable operator.
Determinism vs. Emergent Behavior in CX
Emergent behavior is often celebrated in AI research. In CX, it is usually a liability.
Customers do not want:
Creative interpretations of policy
Novel escalation strategies
Personalized but inconsistent journeys
Determinism constrains emergence to expression, not action.
Canonical Agentic CX Architecture
Mature agentic CX systems typically separate concerns:
Deterministic Orchestration Layer
Defines allowable actions
Enforces sequencing rules
Governs state transitions
Probabilistic Reasoning Layer
Interprets intent
Handles ambiguity
Generative Interaction Layer
Communicates with customers
Explains actions
Determinism anchors the system; intelligence operates within bounds.
Real-World CX Examples
Example 1: End-to-End Billing Resolution Agent
An agentic system resolves billing disputes autonomously.
Deterministic logic controls:
Eligibility checks
Maximum credits
Required verification steps
Agentic behavior sequences actions:
Retrieve invoice
Apply adjustment
Notify customer
Two identical disputes follow the same path, regardless of timing or channel.
Example 2: Proactive Service Outreach
An AI agent monitors service degradation and proactively contacts customers.
Deterministic inference ensures:
Outreach thresholds are consistent
Priority ordering is fair
Messaging triggers are stable
Without determinism, customers perceive favoritism or randomness.
Example 3: Escalation Management
An agentic CX system decides when to escalate to a human.
Deterministic rules govern:
Sentiment thresholds
Time-in-journey limits
Regulatory triggers
This prevents over-escalation, under-escalation, and agent mistrust.
Debugging, Auditability, and Learning
Agentic systems without determinism are nearly impossible to debug.
Deterministic inference enables:
Replay of customer journeys
Root-cause analysis
Safe iteration on rules and models
This is essential for continuous CX improvement.
Part 9: Strategic CX Implications
Deterministic inference is not merely a technical implementation detail – it is a strategic enabler that determines whether AI strengthens or destabilizes a customer experience operating model.
At scale, CX strategy is less about individual interactions and more about repeatable experience outcomes. Determinism is what allows AI-driven CX to move from experimentation to institutional capability.
Defining Strategic CX Implications
From a CX leadership perspective, a strategic implication is not about what the AI can do, but:
How reliably it can do it
How safely it can scale
How well it aligns with brand, policy, and regulation
Deterministic inference directly influences these dimensions.
1. Scalable Personalization Without Fragmentation
Scalable personalization means:
Delivering tailored experiences to millions of customers without introducing inconsistency, inequity, or operational chaos.
Without determinism:
Personalization feels random
Customers struggle to understand why they received a specific treatment
Frontline teams cannot explain or defend outcomes
With deterministic inference:
Personalization logic is explicit and repeatable
Customers with similar profiles experience similar journeys
Variations are intentional, not accidental
Real-world example: A telecom provider personalizes retention offers.
Deterministic logic assigns offer tiers based on tenure, usage, and churn risk
Generative AI personalizes messaging tone and framing
Customers perceive personalization as thoughtful—not arbitrary.
2. Governable Automation and Risk Management
Governable automation refers to:
The ability to control, audit, and modify automated CX behavior without halting operations.
Deterministic inference enables:
Clear ownership of decision logic
Predictable effects of policy changes
Safe rollout and rollback of AI capabilities
Without determinism, automation becomes opaque and risky.
Real-world example: An insurance provider automates claims triage.
Deterministic inference governs eligibility and routing
Changes to rules can be simulated before deployment
This reduces regulatory exposure while improving cycle time.
3. Experience Quality Assurance at Scale
Traditional CX quality assurance relies on sampling human interactions.
AI-driven CX requires:
System-level assurance that experiences conform to defined standards.
Deterministic inference allows organizations to:
Test AI behavior before release
Detect drift when logic changes
Guarantee experience consistency across channels
Real-world example: A bank tests AI responses to fee disputes across all channels.
Deterministic logic ensures identical outcomes in chat, voice, and branch support
QA focuses on tone and clarity, not decision variance
4. Regulatory Defensibility and Audit Readiness
In regulated industries, CX decisions are often legally material.
Deterministic inference enables:
Reproduction of past decisions
Clear explanation of why an outcome occurred
Evidence that policies are applied uniformly
Real-world example: A lender responds to a customer complaint about loan denial.
Deterministic inference allows the exact decision path to be replayed
The institution demonstrates fairness and compliance
This shifts AI from liability to asset.
5. Organizational Alignment and Operating Model Stability
CX failures are often organizational, not technical.
Deterministic inference supports:
Alignment between policy, legal, CX, and operations
Clear translation of business intent into system behavior
Reduced reliance on tribal knowledge
Real-world example: A global retailer standardizes return policies across regions.
The experience remains consistent even as organizations scale.
6. Economic Predictability and ROI Measurement
From a strategic standpoint, leaders must justify AI investments.
Deterministic inference enables:
Predictable cost-to-serve
Stable deflection and containment metrics
Reliable attribution of outcomes to decisions
Without determinism, ROI analysis becomes speculative.
Real-world example: A contact center deploys AI-assisted resolution.
Deterministic guidance ensures consistent handling time reductions
Leadership can confidently scale investment
Part 10: The Future of Deterministic Inference in CX
Key trends include:
Experience Governance by Design – A proactive approach that embeds compliance, ethics, risk management, and operational rules directly into the creation of systems, products, or services from the very start, making them inherently aligned with desired outcomes, rather than adding them as an afterthought. It shifts governance from being a restrictive layer to a foundational enabler, ensuring that systems are built to be effective, trustworthy, and sustainable, guiding user behavior and decision-making intuitively.
Hybrid Experience Architectures – A strategic framework that combines and integrates different computing, physical, or organizational elements to create a unified, flexible, and optimized user experience. The specific definition varies by context, but it fundamentally involves leveraging the strengths of disparate systems through seamless integration and orchestration.
Trust as a Differentiator – A brand’s proven reliability, integrity, and commitment to its promises become the primary reason customers choose it over competitors, especially when products are similar, leading to higher prices, reduced friction, and increased loyalty by building confidence and reducing perceived risk. It’s the belief that a company will act in the customer’s best interest, providing a competitive advantage difficult to replicate.
Conclusion: Determinism as the Backbone of Trusted CX
Deterministic inference is foundational to trustworthy, scalable, AI-driven customer experience. It ensures that intelligence does not come at the cost of consistency—and that automation enhances, rather than undermines, customer trust.
As AI becomes inseparable from CX, determinism will increasingly define which organizations deliver coherent, defensible, and differentiated experiences and which struggle with fragmentation and erosion of trust.
Please join us on (Spotify) as we discuss this and other AI / CX topics.
Artificial intelligence may be the most powerful technology of the century—but behind the demos, the breakthroughs, and the trillion-dollar valuations, a very different story is unfolding in the credit markets. CDS traders, structured finance desks, and risk analysts have quietly begun hedging against a scenario the broader industry refuses to contemplate: that the AI boom may be running ahead of its cash flows, its customers, and its capacity to sustain the massive debt fueling its datacenter expansion. The Oracle–OpenAI megadeals, trillion-dollar infrastructure plans, and unprecedented borrowing across the sector may represent the future—or the early architecture of a credit bubble that will only be obvious in hindsight. As equity markets celebrate the AI revolution, the people paid to price risk are asking a far more sobering question: What if the AI boom is not underpriced opportunity, but overleveraged optimism?
Over the last few months, we’ve seen a sharp rise in credit default swap (CDS) activity tied to large tech names funding massive AI data center expansions. Trading volume in CDS linked to some hyperscalers has surged, and the cost of protection on Oracle’s debt has more than doubled since early fall, as banks and asset managers hedge their exposure to AI-linked credit risk. Bloomberg
At the same time, deals like Oracle’s reported $300B+ cloud contract with OpenAI and OpenAI’s broader trillion-dollar infrastructure commitments have become emblematic of the question hanging over the entire sector:
Are we watching the early signs of an AI credit bubble, or just the normal stress of funding a once-in-a-generation infrastructure build-out?
This post takes a hard, finance-literate look at that question—through the lens of datacenter debt, CDS pricing, and the gap between AI revenue stories and today’s cash flows.
1. Credit Default Swaps: The Market’s Geiger Counter for Risk
A quick refresher: CDS are insurance contracts on debt. The buyer pays a premium; the seller pays out if the underlying borrower defaults or restructures. In 2008, CDS became infamous as synthetic ways to bet on mortgage credit collapsing.
In a normal environment:
Tight CDS spreads ≈ markets view default risk as low
Widening CDS spreads ≈ rising concern about leverage, cash flow, or concentration risk
The recent spike in CDS pricing and volume around certain AI-exposed firms—especially Oracle—is telling:
The cost of CDS protection on Oracle has more than doubled since September.
Trading volume in Oracle CDS reached roughly $4.2B over a six-week period, driven largely by banks hedging their loan and bond exposure. Bloomberg
This doesn’t mean markets are predicting imminent default. It does mean AI-related leverage has become large enough that sophisticated players are no longer comfortable being naked long.
In other words: the credit market is now pricing an AI downside scenario as non-trivial.
2. The Oracle–OpenAI Megadeal: Transformational or Overextended?
The flashpoint is Oracle’s partnership with OpenAI.
Public reporting suggests a multi-hundred-billion-dollar cloud infrastructure deal, often cited around $300B over several years, positioning Oracle Cloud Infrastructure (OCI) as a key pillar of OpenAI’s long-term compute strategy. CIO+1
In parallel, OpenAI, Oracle and partners like SoftBank and MGX have rolled the “Stargate” concept into a massive U.S. data-center platform:
OpenAI, Oracle, and SoftBank have collectively announced five new U.S. data center sites within the Stargate program.
Together with Abilene and other projects, Stargate is targeting ~7 GW of capacity and over $400B in investment over three years. OpenAI
Separate analyses estimate OpenAI has committed to $1.15T in hardware and cloud infrastructure spend from 2025–2035 across Oracle, Microsoft, Broadcom, Nvidia, AMD, AWS, and CoreWeave. Tomasz Tunguz
These numbers are staggering even by hyperscaler standards.
From Oracle’s perspective, the deal is a once-in-a-lifetime chance to leapfrog from “ERP/database incumbent” into the top tier of cloud and AI infrastructure providers. CIO+1
From a credit perspective, it’s something else: a highly concentrated, multi-hundred-billion-dollar bet on a small number of counterparties and a still-forming market.
Moody’s has already flagged Oracle’s AI contracts—especially with OpenAI—as a material source of counterparty risk and leverage pressure, warning that Oracle’s debt could grow faster than EBITDA, potentially pushing leverage to ~4x and keeping free cash flow negative for an extended period. Reuters
That’s exactly the kind of language that makes CDS desks sharpen their pencils.
3. How the AI Datacenter Boom Is Being Funded: Debt, Everywhere
This isn’t just about Oracle. Across the ecosystem, AI infrastructure is increasingly funded with debt:
Data center debt issuance has reportedly more than doubled, with roughly $25B in AI-related data center bonds in a recent period and projections of $2.9T in cumulative AI-related data center capex between 2025–2028, about half of it reliant on external financing. The Economic Times
Oracle is estimated by some analysts to need ~$100B in new borrowing over four years to support AI-driven datacenter build-outs. Channel Futures
Oracle has also tapped banks for a mix of $38B in loans and $18B in bond issuance in recent financing waves. Yahoo Finance+1
Meta reportedly issued around $30B in financing for a single Louisiana AI data center campus. Yahoo Finance
Simultaneously, OpenAI’s infrastructure ambitions are escalating:
The Stargate program alone is described as a $500B+ project consuming up to 10 GW of power, more than the current energy usage of New York City. Business Insider
OpenAI has been reported as needing around $400B in financing in the near term to keep these plans on track and has already signed contracts that sum to roughly $1T in 2025 alone, including with Oracle. Ed Zitron’s Where’s Your Ed At+1
Layer on top of that the broader AI capex curve: annual AI data center spending forecast to rise from $315B in 2024 to nearly $1.1T by 2028.The Economic Times
This is not an incremental technology refresh. It’s a credit-driven, multi-trillion-dollar restructuring of global compute and power infrastructure.
The core concern: are the corresponding revenue streams being projected with commensurate realism?
4. CDS as a Real-Time Referendum on AI Revenue Assumptions
CDS traders don’t care about AI narrative—they care about cash-flow coverage and downside scenarios.
Recent signals:
The cost of CDS on Oracle’s bonds has surged, effectively doubling since September, as banks and money managers buy protection. Bloomberg
Trading volumes in Oracle CDS have climbed into multi-billion-dollar territory over short windows, unusual for a company historically viewed as a relatively stable, investment-grade software vendor. Bloomberg
What are they worried about?
Concentration Risk Oracle’s AI cloud future is heavily tied to a small number of mega contracts—notably OpenAI. If even one of those counterparties slows consumption, renegotiates, or fails to ramp as expected, the revenue side of Oracle’s AI capex story can wobble quickly.
Timing Mismatch Debt service is fixed; AI demand is not. Datacenters must be financed and built years before they are fully utilized. A delay in AI monetization—either at OpenAI or among Oracle’s broader enterprise AI customer base—still leaves Oracle servicing large, inflexible liabilities.
Macro Sensitivity If economic growth slows, enterprises might pull back on AI experimentation and cloud migration, potentially flattening the growth curve Oracle and others are currently underwriting.
CDS spreads are telling us: credit markets see non-zero probability that AI revenue ramps will fall short of the most optimistic scenarios.
5. Are AI Revenue Projections Outrunning Reality?
The bull case says: These are long-dated, capacity-style deals. AI demand will eventually fill every rack; cloud AI revenue will justify today’s capex.
The skeptic’s view surfaces several friction points:
OpenAI’s Monetization vs. Burn Rate
OpenAI reportedly spent $6.7B on R&D in the first half of 2025, with the majority historically going to experimental training runs rather than production models. Ed Zitron’s Where’s Your Ed At Parallel commentary suggests OpenAI needs hundreds of billions in additional funding in short order to sustain its infrastructure strategy. Ed Zitron’s Where’s Your Ed At
While product revenue is growing, it’s not yet obvious that it can service trillion-scale hardware commitments without continued external capital.
Enterprise AI Adoption Is Still Shallow Most enterprises remain stuck in pilot purgatory: small proof-of-concepts, modest copilots, limited workflow redesign. The gap between “we’re experimenting with AI” and “AI drives 20–30% of our margin expansion” is still wide.
Model Efficiency Is Improving Fast If smaller, more efficient models close the performance gap with frontier models, demand for maximal compute may underperform expectations. That would pressure utilization assumptions baked into multi-gigawatt campuses and decade-long hardware contracts.
Regulation & Trust Safety, privacy, and sector-specific regulation (especially in finance, healthcare, public sector) may slow high-margin, high-scale AI deployments, further delaying returns.
Taken together, this looks familiar: optimistic top-line projections backed by debt-financed capacity, with adoption and unit economics still in flux.
That’s exactly the kind of mismatch that fuels bubble narratives.
6. Theory: Is This a Classic Minsky Moment in the Making?
funding forecasts that assume near-frictionless adoption
The profit-taking phase may be starting—not via equity selling, but via:
CDS buying
spread widening
stricter credit underwriting for AI-exposed borrowers
From a Minsky lens, the CDS market’s behavior looks exactly like sophisticated participants quietly de-risking while the public narrative stays bullish.
That doesn’t guarantee panic. But it does raise a question: If AI infrastructure build-outs stumble, where does the stress show up first—equity, debt, or both?
7. Counterpoint: This Might Be Railroads, Not Subprime
There is a credible argument that today’s AI debt binge, while risky, is fundamentally different from 2008-style toxic leverage:
These projects fund real, productive assets—datacenters, power infrastructure, chips—rather than synthetic mortgage instruments.
Even if AI demand underperforms, much of this capacity can be repurposed for:
traditional cloud workloads
high-performance computing
scientific simulation
media and gaming workloads
Historically, large infrastructure bubbles (e.g., railroads, telecom fiber) left behind valuable physical networks, even after investors in specific securities were wiped out.
Similarly, AI infrastructure may outlast the most aggressive revenue assumptions:
Oracle’s OCI investments improve its position in non-AI cloud as well. The Motley Fool+1
Power grid upgrades and new energy contracts have value far beyond AI alone. Bloomberg+1
In this framing, the “AI bubble” might hurt capital providers, but still accelerate broader digital and energy infrastructure for decades.
8. So Is the AI Bubble Real—or Rooted in Uncertainty?
A mature, evidence-based view has to hold two ideas at once:
Yes, there are clear bubble dynamics in parts of the AI stack.
Datacenter capex and debt are growing at extraordinary rates. The Economic Times+1
Oracle’s CDS and Moody’s commentary show real concern around concentration risk and leverage. Bloomberg+1
OpenAI’s hardware commitments and funding needs are unprecedented for a private company with a still-evolving business model. Tomasz Tunguz+1
No, this is not a pure replay of 2008 or 2000.
Infrastructure assets are real and broadly useful.
AI is already delivering tangible value in many production settings, even if not yet at economy-wide scale.
The biggest risks look concentrated (Oracle, key AI labs, certain data center REITs and lenders), not systemic across the entire financial system—at least for now.
A Practical Decision Framework for the Reader
To form your own view on the AI bubble question, ask:
Revenue vs. Debt: Does the company’s contracted and realistic revenue support its AI-related debt load under conservative utilization and pricing assumptions?
Concentration Risk: How dependent is the business on one or two AI counterparties or a single class of model?
Reusability of Assets: If AI demand flattens, can its datacenters, power agreements, and hardware be repurposed for other workloads?
Market Signals: Are CDS spreads widening? Are ratings agencies flagging leverage? Are banks increasingly hedging exposure?
Adoption Reality vs. Narrative: Do enterprise customers show real, scaled AI adoption, or still mostly pilots, experimentation, and “AI tourism”?
9. Closing Thought: Bubble or Not, Credit Is Now the Real Story
Equity markets tell you what investors hope will happen. The CDS market tells you what they’re afraid might happen.
Right now, credit markets are signaling that AI’s infrastructure bets are big enough, and leveraged enough, that the downside can’t be ignored.
Whether you conclude that we’re in an AI bubble—or just at the messy financing stage of a transformational technology—depends on how you weigh:
Trillion-dollar infrastructure commitments vs. real adoption
Physical asset durability vs. concentration risk
Long-term productivity gains vs. short-term overbuild
But one thing is increasingly clear: If the AI era does end in a crisis, it won’t start with a model failure. It will start with a credit event.
For months now, a quiet tension has been building in boardrooms, engineering labs, and investor circles. On one side are the evangelists—those who see AI as the most transformative platform shift since electrification. On the other side sit the skeptics—analysts, CFOs, and surprisingly, even many technologists themselves—who argue that returns have yet to materialize at the scale the hype suggests.
Under this tension lies a critical question: Is today’s AI boom structurally similar to the dot-com bubble of 2000 or the credit-fueled collapse of 2008? Or are we projecting old crises onto a frontier technology whose economics simply operate by different rules?
This question matters deeply. If we are indeed replaying history, capital will dry up, valuations will deflate, and entire markets will neutralize. But if the skeptics are misreading the signals, then we may be at the base of a multi-decade innovation curve—one that rewards contrarian believers.
Let’s unpack both possibilities with clarity, data, and context.
1. The Dot-Com Parallel: Exponential Valuations, Minimal Cash Flow, and Over-Narrated Futures
The comparison to the dot-com era is the most popular narrative among skeptics. It’s not hard to see why.
1.1. Startups With Valuations Outrunning Their Revenue
During the dot-com boom, revenue-light companies—eToys, Pets.com, Webvan—reached massive valuations with little proven demand. Today, many AI model-centric startups are experiencing a similar phenomenon:
Enormous valuations built primarily on “strategic potential,” not realized revenue
Extremely high compute burn rates
Reliance on outside capital to fund model training cycles
No defensible moat beyond temporary performance advantages
This is the classic pattern of a bubble: cheap capital + narrative dominance + no proven path to sustainable margins.
1.2. Infrastructure Outpacing Real Adoption
In the late 90s, telecom and datacenter expansion outpaced actual Internet usage. Today, hyperscalers and AI-focused cloud providers are pouring billions into:
GPU clusters
Data center expansion
Power procurement deals
Water-cooled rack infrastructure
Hydrogen and nuclear plans
Yet enterprise adoption remains shallow. Few companies have operationalized AI beyond experimentation. CFOs are cutting budgets. CIOs are tightening governance. Many “enterprise AI transformation” programs have delivered underwhelming impact.
1.3. The Hype Premium
Just as the 1999 investor decks promised digital utopia, 2024–2025 decks promise:
Fully autonomous enterprises
Real-time copilots everywhere
Self-optimizing supply chains
AI replacing entire departments
The irony? Most enterprises today can’t even get their data pipelines, governance, or taxonomy stable enough for AI to work reliably.
The parallels are real—and unsettling.
2. The 2008 Parallel: Systemic Concentration Risk and Capital Misallocation
The 2008 financial crisis was not just about bad mortgages; it was about structural fragility, over-leveraged bets, and market concentration hiding systemic vulnerabilities.
The AI ecosystem shows similar warning signs.
2.1. Extreme Concentration in a Few Companies
Three companies provide the majority of the world’s AI computational capacity. A handful of frontier labs control model innovation. A small cluster of chip providers (NVIDIA, TSMC, ASML) underpin global AI scaling.
This resembles the 2008 concentration of risk among a small number of banks and insurers.
2.2. High Leverage, Just Not in the Traditional Sense
In 2008, leverage came from debt. In 2025, leverage comes from infrastructure obligations:
Multi-billion-dollar GPU pre-orders
10–20-year datacenter power commitments
Long-term cloud contracts
Vast sunk costs in training pipelines
If demand for frontier-scale AI slows—or simply grows at a more “normal” rate than predicted—this leverage becomes a liability.
2.3. Derivative Markets for AI Compute
There are early signs of compute futures markets, GPU leasing entities, and synthetic capacity pools. While innovative, they introduce financial abstraction that rhymes with the derivative cascades of 2008.
If core demand falters, the secondary financial structures collapse first—potentially dragging the core ecosystem down with them.
3. The Skeptic’s Argument: ROI Has Not Materialized
Every downturn begins with unmet expectations.
Across industries, the story is consistent:
POCs never scaled
Data was ungoverned
Model performance degraded in the real world
Accuracy thresholds were not reached
Cost of inference exploded unexpectedly
GenAI copilots produced hallucinations
The “skills gap” became larger than the technology gap
For many early adopters, the hard truth is this: AI delivered interesting prototypes, not transformational outcomes.
The skepticism is justified.
4. The Optimist’s Counterargument: Unlike 2000 or 2008, AI Has Real Utility Today
This is the key difference.
The dot-com bubble burst because the infrastructure was not ready. The 2008 crisis collapsed because the underlying assets were toxic.
But with AI:
The technology works
The usage is real
Productivity gains exist (though uneven)
Infrastructure is scaling in predictable ways
Fundamental demand for automation is increasing
The cost curve for compute is slowly (but steadily) compressing
New classes of models (small, multimodal, agentic) are lowering barriers
If the dot-com era had delivered search, cloud, mobile apps, or digital payments in its first 24 months, the bubble might not have burst as severely.
AI is already delivering these equivalents.
5. The Key Question: Is the Value Accruing to the Wrong Layer?
Most failed adoption stems from a structural misalignment: Value is accruing at the infrastructure and model layers—not the enterprise implementation layer.
In other words:
Chipmakers profit
Hyperscalers profit
Frontier labs attract capital
Model inferencing platforms grow
But enterprises—those expected to realize the gains—are stuck in slow, expensive adoption cycles.
This creates the illusion that AI isn’t working, even though the economics are functioning perfectly for the suppliers.
This misalignment is the root of the skepticism.
6. So, Is This a Bubble? The Most Honest Answer Is “It Depends on the Layer You’re Looking At.”
The AI economy is not monolithic. It is a stacked ecosystem, and each layer has entirely different economics, maturity levels, and risk profiles. Unlike the dot-com era—where nearly all companies were overvalued—or the 2008 crisis—where systemic fragility sat beneath every asset class—the AI landscape contains asymmetric risk pockets.
Below is a deeper, more granular breakdown of where the real exposure lies.
6.1. High-Risk Areas: Where Speculation Has Outrun Fundamentals
Frontier-Model Startups
Large-scale model development resembles the burn patterns of failed dot-com startups: high cost, unclear moat.
Examples:
Startups claiming they will “rival OpenAI or Anthropic” while spending $200M/year on GPUs with no distribution channel.
Companies raising at $2B–$5B valuations based solely on benchmark performance—not paying customers.
“Foundation model challengers” whose only moat is temporary model quality, a rapidly decaying advantage.
Why High Risk: Training costs scale faster than revenue. The winner-take-most dynamics favor incumbents with established data, compute, and brand trust.
GPU Leasing and Compute Arbitrage Markets
A growing field of companies buy GPUs, lease them out at premium pricing, and arbitrage compute scarcity.
Examples:
Firms raising hundreds of millions to buy A100/H100 inventory and rent it to AI labs.
Secondary GPU futures markets where investors speculate on H200 availability.
Brokers offering “synthetic compute capacity” based on future hardware reservations.
Why High Risk: If model efficiency improves (e.g., SSMs, low-rank adaptation, pruning), demand for brute-force compute shrinks. Exactly like mortgage-backed securities in 2008, these players rely on sustained upstream demand. Any slowdown collapses margins instantly.
Thin-Moat Copilot Startups
Dozens of companies offer AI copilots for finance, HR, legal, marketing, or CRM tasks, all using similar APIs and LLMs.
Examples:
A GenAI sales assistant with no proprietary data advantage.
AI email-writing platforms that replicate features inside Microsoft 365 or Google Workspace.
Meeting transcription tools that face commoditization from Zoom, Teams, and Meet.
Why High Risk: Every hyperscaler and SaaS platform is integrating basic GenAI natively. The standalone apps risk the same fate as 1999 “shopping portals” crushed by Amazon and eBay.
AI-First Consulting Firms Without Deep Engineering Capability
These firms promise to deliver operationalized AI outcomes but rely on subcontracted talent or low-code wrappers.
Examples:
Consultancies selling multimillion-dollar “AI Roadmaps” without offering real ML engineering.
Strategy firms building prototypes that cannot scale to production.
Boutique shops that lock clients into expensive retainer contracts but produce only slideware.
Why High Risk: Once AI budgets tighten, these firms will be the first to lose contracts. We already see this in enterprise reductions in experimental GenAI spend.
6.2. Moderate-Risk Areas: Real Value, but Timing and Execution Matter
Hyperscaler AI Services
Azure, AWS, and GCP are pouring billions into GPU clusters, frontier model partnerships, and vertical AI services.
Examples:
Azure’s $10B compute deal to power OpenAI.
Google’s massive TPU v5 investments.
AWS’s partnership with Anthropic and its Bedrock ecosystem.
Why Moderate Risk: Demand is real—but currently inflated by POCs, “AI tourism,” and corporate FOMO. As 2025–2027 budgets normalize, utilization rates will determine whether these investments remain accretive or become stranded capacity.
Agentic Workflow Platforms
Companies offering autonomous agents that execute multi-step processes—procurement workflows, customer support actions, claims handling, etc.
Examples:
Platforms like Adept, Mesh, or Parabola that orchestrate multi-step tasks.
Autonomous code refactoring assistants.
Agent frameworks that run long-lived processes with minimal human supervision.
Why Moderate Risk: High upside, but adoption depends on organizations redesigning workflows—not just plugging in AI. The technology is promising, but enterprises must evolve operating models to avoid compliance, auditability, and reliability risks.
AI Middleware and Integration Platforms
Businesses betting on becoming the “plumbing” layer between enterprise systems and LLMs.
Examples:
Data orchestration layers for grounding LLMs in ERP/CRM systems.
Tools like LangChain, LlamaIndex, or enterprise RAG frameworks.
Vector database ecosystems.
Why Moderate Risk: Middleware markets historically become winner-take-few. There will be consolidation, and many players at today’s valuations will not survive the culling.
Data Labeling, Curation, and Synthetic Data Providers
Essential today, but cost structures will evolve.
Examples:
Large annotation farms like Scale AI or Sama.
Synthetic data generators for vision or robotics.
Rater-as-a-service providers for safety tuning.
Why Moderate Risk: If self-supervision, synthetic scaling, or weak-to-strong generalization trends hold, demand for human labeling will tighten.
6.3. Low-Risk Areas: Where the Value Is Durable and Non-Speculative
Semiconductors and Chip Supply Chain
Regardless of hype cycles, demand for accelerated compute is structurally increasing across robotics, simulation, ASR, RL, and multimodal applications.
Examples:
NVIDIA’s dominance in training and inference.
TSMC’s critical role in advanced node manufacturing.
ASML’s EUV monopoly.
Why Low Risk: These layers supply the entire computation economy—not just AI. Even if the AI bubble deflates, GPU demand remains supported by scientific computing, gaming, simulation, and defense.
Datacenter Infrastructure and Energy Providers
The AI boom is fundamentally a power and cooling problem, not just a model problem.
Examples:
Utility-scale datacenter expansions in Iowa, Oregon, and Sweden.
Liquid-cooled rack deployments.
Multibillion-dollar energy agreements with nuclear and hydro providers.
Why Low Risk: AI workloads are power-intensive, and even with efficiency improvements, energy demand continues rising. This resembles investing in railroads or highways rather than betting on any single car company.
Developer Productivity Tools and MLOps Platforms
Tools that streamline model deployment, monitoring, safety, versioning, evaluation, and inference optimization.
Examples:
Platforms like Weights & Biases, Mosaic, or OctoML.
Code generation assistants embedded in IDEs.
Compiler-level optimizers for inference efficiency.
Why Low Risk: Demand is stable and expanding. Every model builder and enterprise team needs these tools, regardless of who wins the frontier model race.
Enterprise Data Modernization and Taxonomy / Grounding Infrastructure
Organizations with trustworthy data environments consistently outperform in AI deployment.
Examples:
Data mesh architectures.
Structured metadata frameworks.
RAG pipelines grounded in canonical ERP/CRM data.
Master data governance platforms.
Why Low Risk: Even if AI adoption slows, these investments create value. If AI adoption accelerates, these investments become prerequisites.
6.4. The Core Insight: We Are Experiencing a Layered Bubble, Not a Systemic One
Unlike 2000, not everything is overpriced. Unlike 2008, the fragility is not systemic.
High-risk layers will deflate. Low-risk layers will remain foundational. Moderate-risk layers will consolidate.
This asymmetry is what makes the current AI landscape so complex—and so intellectually interesting. Investors must analyze each layer independently, not treat “AI” as a uniform asset class.
7. The Insight Most People Miss: AI Fails Slowly, Then Succeeds All at Once
Most emerging technologies follow an adoption curve. AI’s curve is different because it carries a unique duality: it is simultaneously underperforming and overperforming expectations. This paradox is confusing to executives and investors—but essential to understand if you want to avoid incorrect conclusions about a bubble.
The pattern that best explains what’s happening today comes from complex systems: AI failure happens gradually and for predictable reasons. AI success happens abruptly and only after those reasons are removed.
Let’s break that down with real examples.
7.1. Why Early AI Initiatives Fail Slowly (and Predictably)
AI doesn’t fail because the models don’t work. AI fails because the surrounding environment isn’t ready.
Early adopters typically discover that AI performance is not the limiting factor — their operating model is.
Examples:
A Fortune 100 retailer deploys a customer-service copilot but cannot use it because their knowledge base is out-of-date by 18 months.
A large insurer automates claim intake but still routes cases through approval committees designed for pre-AI workflows, doubling the cycle time.
A manufacturing firm deploys predictive maintenance models but has no spare parts logistics framework to act on the predictions.
Insight: These failures are not technical—they’re organizational design failures. They happen slowly because the organization tries to “bolt on AI” without changing the system underneath.
Failure Mode #2: Data Architecture Is Inadequate for Real-World AI
Early pilots often work brilliantly in controlled environments and fail spectacularly in production.
Examples:
A bank’s fraud detection model performs well in testing but collapses in production because customer metadata schemas differ across regions.
A pharmaceutical company’s RAG system references staging data and gives perfect answers—but goes wildly off-script when pointed at messy real-world datasets.
A telecom provider’s churn model fails because the CRM timestamps are inconsistent by timezone, causing silent degradation.
Insight: The majority of “AI doesn’t work” claims stem from data inconsistencies, not model limitations. These failures accumulate over months until the program is quietly paused.
Failure Mode #3: Economic Assumptions Are Misaligned
Many early-version AI deployments were too expensive to scale.
Examples:
A customer-support bot costs $0.38 per interaction to run—higher than a human agent using legacy CRM tools.
A legal AI summarization system consumes 80% of its cloud budget just parsing PDFs.
An internal code assistant saves developers time but increases inference charges by a factor of 20.
Insight: AI’s ROI often looks negative early not because the value is small—but because the first wave of implementation is structurally inefficient.
7.2. Why Late-Stage AI Success Happens Abruptly (and Often Quietly)
Here’s the counterintuitive part: once the underlying constraints are fixed, AI does not improve linearly—it improves exponentially.
This is the core insight: AI returns follow a step-function pattern, not a gradual curve.
Below are examples from organizations that achieved this transition.
Success Mode #1: When Data Quality Hits a Threshold, AI Value Explodes
Once a company reaches critical data readiness, the same models that previously looked inadequate suddenly generate outsized results.
Examples:
A logistics provider reduces routing complexity from 29 variables to 11 canonical features. Their route-optimization AI—previously unreliable—now saves $48M annually in fuel costs.
A healthcare payer consolidates 14 data warehouses into a unified claims store. Their fraud model accuracy jumps from 62% to 91% without retraining.
A consumer goods company builds a metadata governance layer for product descriptions. Their search engine produces a 22% lift in conversions using the same embedding model.
Insight: The value was always there. The pipes were not. Once the pipes are fixed, value accelerates faster than organizations expect.
Success Mode #2: When AI Becomes Embedded, Not Added On, ROI Becomes Structural
AI only becomes transformative when it is built into workflows—not layered on top of them.
Examples:
A call center doesn’t deploy an “agent copilot.” Instead, it rebuilds the entire workflow so the copilot becomes the first reader of every case. Average handle time drops 30%.
A bank redesigns underwriting from scratch using probabilistic scoring + agentic verification. Loan processing time goes from 15 days to 4 hours.
A global engineering firm reorganizes R&D around AI-driven simulation loops. Their product iteration cycle compresses from 18 months to 10 weeks.
Insight: These are not incremental improvements—they are order-of-magnitude reductions in time, cost, or complexity.
This is why success appears sudden: Organizations go from “AI isn’t working” to “we can’t operate without AI” very quickly.
Success Mode #3: When Costs Normalize, Entire Use Cases Become Economically Viable Overnight
Just like Moore’s Law enabled new hardware categories, AI cost curves unlock entirely new use cases once they cross economic thresholds.
Examples:
Code generation becomes viable when inference cost falls below $1 per developer per day.
Automated video analysis becomes scalable when multimodal inference drops under $0.10/minute.
Autonomous agents become attractive only when long-context models can run persistent sessions for less than $0.01/token.
Insight: Small improvements in cost + efficiency create massive new addressable markets.
That is why success feels instantaneous—entire categories cross feasibility thresholds at once.
7.3. The Core Insight: Early Failures Are Not Evidence AI Won’t Work—They Are Evidence of Unrealistic Expectations
Executives often misinterpret early failure as proof that AI is overhyped.
In reality, it signals that:
The organization treated AI as a feature, not a process redesign
The data estate was not production-grade
The economics were modeled on today’s costs instead of future costs
Teams were structured around old workflows
KPIs measured activity, not transformation
Governance frameworks were legacy-first, not AI-first
This is the equivalent of judging the automobile by how well it performs without roads.
7.4. The Decision-Driving Question: Are You Judging AI on Its Current State or Its Trajectory?
Technologists tend to overestimate short-term capability but underestimate long-term convergence. Financial leaders tend to anchor decisions to early ROI data, ignoring the compounding nature of system improvements.
The real dividing line between winners and losers in this era will be determined by one question:
Do you interpret early AI failures as a ceiling—or as the ground floor of a system still under construction?
If you believe AI’s early failures represent the ceiling:
You’ll delay or reduce investments and minimize exposure, potentially avoiding overhyped initiatives but risking structural disadvantage later.
If you believe AI’s early failures represent the floor:
You’ll invest in foundational capabilities—data quality, taxonomy, workflows, governance—knowing the step-change returns come later.
7.5. The Pattern Is Clear: AI Transformation Is Nonlinear, Not Incremental
Most organizations are stuck in Phase 1. A few are transitioning to Phase 2. Almost none are in Phase 3 yet.
That’s why the market looks confused.
8. The Mature Investor’s View: AI Is Overpriced in Some Layers, Underestimated in Others
Most conversations about an “AI bubble” focus on valuations or hype cycles—but mature investors think in structural patterns, not headlines. The nuanced view is that AI contains pockets of overvaluation, pockets of undervaluation, and pockets of durable long-term value, all coexisting within the same ecosystem.
This section expands on how sophisticated investors separate noise from signal—and why this perspective is grounded in history, not optimism.
8.1. The Dot-Com Analogy: Understanding Overvaluation in Context
In 1999, investors were not wrong about the Internet’s long-term impact. They were only wrong about:
Where value would accrue
How fast returns would materialize
Which companies were positioned to survive
This distinction is essential.
Historical Pattern: Frontier Technologies Overprice the Application Layer First
During the dot-com era:
Hundreds of consumer “Internet portals” were funded
E-commerce concepts attracted billions without supply-chain capability
Vertical marketplaces (e.g., online groceries, pet supplies) captured attention despite weak unit economics
But value didn’t disappear. Instead, it concentrated:
Amazon survived and became the sector winner
Google emerged from the ashes of search-engine overfunding
Salesforce built an entirely new business model on top of web infrastructure
Most of the failed players were replaced by better-capitalized, better-timed entrants
Parallel to AI today: The majority of model-centric startups and thin-moat copilots mirror the “Pets.com phase” of the Internet—early, obvious use cases with the wrong economic foundation.
Investors with historical perspective know this pattern well.
8.2. The 2008 Analogy: Concentration Risk and System Fragility
The financial crisis was not about bad business models—many of the banks were profitable—it was about systemic fragility and hidden leverage.
Sophisticated investors look at AI today and see similar concentration risk:
Training capacity is concentrated in a handful of hyperscalers
GPU supply is dependent on one dominant chip architecture
Advanced node manufacturing is effectively a single point of failure (TSMC)
Frontier model research is consolidated among a few labs
Energy demand rests on long-term commitments with limited flexibility
This doesn’t mean collapse is imminent. But it does mean that the risk is structural, not superficial, mirroring the conditions of 2008.
Historical Pattern: Crises Arise When Everyone Makes the Same Bet
In 2008:
Everyone bet on perpetual housing appreciation
Everyone bought securitized mortgage instruments
Everyone assumed liquidity was infinite
Everyone concentrated their risk without diversification
In 2025 AI:
Everyone is buying GPUs
Everyone is funding LLM-based copilots
Everyone is training models with the same architectures
Everyone is racing to produce the same “agentic workflows”
Mature investors look at this and conclude: The risk is not in AI; the risk is in the homogeneity of strategy.
8.3. Where Mature Investors See Real, Defensible Value
Sophisticated investors don’t chase narratives; they chase structural inevitabilities. They look for value that persists even if the hype collapses.
They ask: If AI growth slowed dramatically, which layers of the ecosystem would still be indispensable?
Inevitable Value Layer #1: Energy and Power Infrastructure
Even if AI adoption stagnated:
Datacenters still need massive amounts of power
Grid upgrades are still required
Cooling and heat-recovery systems remain critical
Energy-efficient hardware remains in demand
Historical parallel: 1840s railway boom Even after the rail bubble burst, the railroads that existed enabled decades of economic growth. The investors who backed infrastructure, not railway speculators, won.
Inevitable Value Layer #2: Semiconductor and Hardware Supply Chains
In every technological boom:
The application layer cycles
The infrastructure layer compounds
Inbound demand for compute is growing across:
Robotics
Simulation
Scientific modeling
Autonomous vehicles
Voice interfaces
Smart manufacturing
National defense
Historical parallel: The post–World War II electronics boom Companies providing foundational components—transistors, integrated circuits, microprocessors—captured durable value even while dozens of electronics brands collapsed.
NVIDIA, TSMC, and ASML now sit in the same structural position that Intel, Fairchild, and Texas Instruments occupied in the 1960s.
Inevitable Value Layer #3: Developer Productivity Infrastructure
This includes:
MLOps
Orchestration tools
Evaluation and monitoring frameworks
Embedding engines
Data governance systems
Experimentation platforms
Why low risk? Because technology complexity always increases over time. Tools that tame complexity always compound in value.
Historical parallel: DevOps tooling post-2008 Even as enterprise IT budgets shrank, tools like GitHub, Jenkins, Docker, and Kubernetes grew because developers needed leverage, not headcount expansion.
8.4. The Underestimated Layer: Enterprise Operational Transformation
Mature investors understand technology S-curves. They know that productivity improvements from major technologies often arrive years after the initial breakthrough.
This is historically proven:
Electrification (1880s) → productivity gains lagged by ~30 years
Computers (1960s) → productivity gains lagged by ~20 years
Broadband Internet (1990s) → productivity gains lagged by ~10 years
Cloud computing (2000s) → real enterprise impact peaked a decade later
Why the lag? Because business processes change slower than technology.
AI is no different.
Sophisticated investors look at the organizational changes required—taxonomy, systems, governance, workflow redesign—and see that enterprise adoption is behind, not because the technology is failing, but because industries move incrementally.
This means enterprise AI is underpriced, not overpriced, in the long run.
8.5. Why This Perspective Is Rational, Not Optimistic
Theory 1: Amara’s Law
We overestimate the impact of technology in the short term and underestimate the impact in the long term. This principle has been validated for:
Industrial automation
Robotics
Renewable energy
Mobile computing
The Internet
Machine learning itself
AI fits this pattern precisely.
Theory 2: The Solow Paradox (and Its Resolution)
In the 1980s, Robert Solow famously said:
“You can see the computer age everywhere but in the productivity statistics.”
The same narrative exists for AI today. Yet when cloud computing, enterprise software, and supply-chain optimization matured, productivity soared.
AI is at the pre-surge stage of the same curve.
Theory 3: General Purpose Technology Lag
Economists classify AI as a General Purpose Technology (GPT), joining:
Electricity
The steam engine
The microprocessor
The Internet
GPTs always produce delayed returns because entire economic sectors must reorganize around them before full value is realized.
Mature investors understand this deeply. They don’t measure ROI on a 12-month cycle. They measure GPT curves in decades.
8.6. The Mature Investor’s Playbook: How They Allocate Capital in AI Today
Sophisticated investors don’t ask, “Is AI a bubble?” They ask:
Question 1: Is the company sitting on a durable layer of the ecosystem?
Examples of “durable” layers:
chips
energy
data gateways
developer platforms
infrastructure software
enterprise system redesign
These have the lowest downside risk.
Question 2: Does the business have a defensible moat that compounds over time?
Example red flags:
Products built purely on frontier models
No proprietary datasets
High inference burn rate
Thin user adoption
Features easily replicated by hyperscalers
Example positive signals:
Proprietary operational data
Grounding pipelines tied to core systems
Embedded workflow integration
Strong enterprise stickiness
Long-term contracts with hyperscalers
Question 3: Is AI a feature of the business, or is it the business?
“AI-as-a-feature” companies almost always get commoditized. “AI-as-infrastructure” companies capture value.
8.7. The Core Conclusion: AI Is Not a Bubble—But Parts of AI Are
The mature investor stance is not about optimism or pessimism. It is about probability-weighted outcomes across different layers of a rapidly evolving stack.
Their guiding logic is based on:
historical evidence
economic theory
defensible market structure
infrastructure dynamics
innovation S-curves
risk concentration patterns
and real, measurable adoption signals
The result?
AI is overpriced at the top, underpriced in the middle, and indispensable at the bottom. The winners will be those who understand where value actually settles—not where hype makes it appear.
9. The Final Thought: We’re Not Repeating 2000 or 2008—We’re Living Through a Hybrid Scenario
The dot-com era teaches us what happens when narratives outpace capability. The 2008 era teaches us what happens when structural fragility is ignored.
The AI era is teaching us something new:
When a technology is both overhyped and under-adopted, over-capitalized and under-realized, the winners are not the loudest pioneers—but the disciplined builders who understand timing, infrastructure economics, and operational readiness.
We are early in the story, not late.
The smartest investors and operators today aren’t asking, “Is this a bubble?” They’re asking: “Where is the bubble forming, and where is the long-term value hiding?”
We discuss this topic and more in detail on (Spotify).
Modern marketing organizations are under pressure to deliver personalized, omnichannel campaigns faster, more efficiently, and at lower cost. Yet many still rely on static taxonomies, underutilized digital asset management (DAM) systems, and external agencies to orchestrate campaigns.
This white paper explores how marketing taxonomy forms the backbone of marketing operations, why it is critical for efficiency and scalability, and how agentic AI can transform it from a static structure into a dynamic, self-optimizing ecosystem. A maturity roadmap illustrates the progression from basic taxonomy adoption to fully autonomous marketing orchestration.
Part 1: Understanding Marketing Taxonomy
What is Marketing Taxonomy?
Marketing taxonomy is the structured system of categories, labels, and metadata that organizes all aspects of a company’s marketing activity. It creates a common language across assets, campaigns, channels, and audiences, enabling marketing teams to operate with efficiency, consistency, and scale.
Legacy Marketing Taxonomy (Static and Manual)
Traditionally, marketing taxonomy has been:
Manually Constructed: Teams manually define categories, naming conventions, and metadata fields. For example, an asset might be tagged as “Fall 2023 Campaign → Social Media → Instagram → Video.”
Rigid: Once established, taxonomies are rarely updated because changes require significant coordination across marketing, IT, and external partners.
Asset-Centric: Focused mostly on file storage and retrieval in DAM systems rather than campaign performance or customer context.
Labor Intensive: Metadata tagging is often delegated to agencies or junior staff, leading to inconsistency and errors.
Example: A global retailer using a legacy DAM might take 2–3 weeks to classify and make new campaign assets globally available, slowing time-to-market. Inconsistent metadata tagging across regions would lead to 30–40% of assets going unused because no one could find them.
Agentic AI-Enabled Marketing Taxonomy (Dynamic and Autonomous)
Agentic AI transforms taxonomy into a living, adaptive system that evolves in real time:
Autonomous Tagging: AI agents ingest and auto-tag assets with consistent metadata at scale. A video uploaded to the DAM might be instantly tagged with attributes such as persona: Gen Z, channel: TikTok, tone: humorous, theme: product launch.
Adaptive Structures: Taxonomies evolve based on performance and market shifts. If short-form video begins outperforming static images, agents adjust taxonomy categories and prioritize surfacing those assets.
Contextual Intelligence: Assets are no longer classified only by campaign but by customer intent, persona, and journey stage. This makes them retrievable in ways humans actually use them.
Self-Optimizing: Agents continuously monitor campaign outcomes, re-tagging assets that drive performance and retiring those that underperform.
Example: A consumer packaged goods (CPG) company deploying agentic AI in its DAM reduced manual tagging by 80%. More importantly, campaigns using AI-classified assets saw a 22% higher engagement rate because agents surfaced creative aligned with active customer segments, not just file location.
Legacy vs. Agentic AI: A Clear Contrast
Dimension
Legacy Taxonomy
Agentic AI-Enabled Taxonomy
Structure
Static, predefined categories
Dynamic, adaptive ontologies evolving in real time
Tagging
Manual, error-prone, inconsistent
Autonomous, consistent, at scale
Focus
Asset storage and retrieval
Customer context, journey stage, performance data
Governance
Reactive compliance checks
Proactive, agent-enforced governance
Speed
Weeks to update or restructure
Minutes to dynamically adjust taxonomy
Value Creation
Efficiency in asset management
Direct impact on engagement, ROI, and speed-to-market
Agency Dependence
Agencies often handle tagging and workflows
Internal agents manage workflows end-to-end
Why This Matters
The shift from legacy taxonomy to agentic AI-enabled taxonomy is more than a technical upgrade — it’s an operational transformation.
Legacy systems treated taxonomy as an administrative tool.
Agentic AI systems treat taxonomy as a strategic growth lever: connecting assets to outcomes, enabling personalization, and allowing organizations to move away from agency-led execution toward self-sufficient, AI-orchestrated campaigns.
Why is Marketing Taxonomy Used?
Taxonomy solves common operational challenges:
Findability & Reusability: Teams quickly locate and repurpose assets, reducing duplication.
Alignment Across Teams: Shared categories improve cross-functional collaboration.
Governance & Compliance: Structured tagging enforces brand and regulatory requirements.
Performance Measurement: Taxonomies connect assets and campaigns to metrics.
Scalability: As organizations expand into new products, channels, and markets, taxonomy prevents operational chaos.
Current Leading Practices in Marketing Taxonomy (Hypothetical Examples)
1. Customer-Centric Taxonomies
Instead of tagging assets by internal campaign codes, leading firms organize them by customer personas, journey stages, and intent signals.
Example: A global consumer electronics brand restructured its taxonomy around 6 buyer personas and 5 customer journey stages. This allowed faster retrieval of persona-specific content. The result was a 27% increase in asset reuse and a 19% improvement in content engagement because teams deployed persona-targeted materials more consistently.
Benchmark: Potentially 64% of B2C marketers using persona-driven taxonomy could report faster campaign alignment across channels.
2. Omnichannel Integration
Taxonomies that unify paid, owned, and earned channels ensure consistency in message and brand execution.
Example: A retail fashion brand linked their DAM taxonomy to email, social, and retail displays. Assets tagged once in the DAM were automatically accessible to all channels. This reduced duplicate creative requests by 35% and cut campaign launch time by 21 days on average.
Benchmark: Firms integrating taxonomy across channels may see a 20–30% uplift in omnichannel conversion rates, because messaging is synchronized and on-brand.
3. Performance-Linked Metadata
Taxonomy isn’t just for classification — it’s being extended to include KPIs and performance metrics as metadata.
Example: A global beverage company embedded click-through rates (CTR) and conversion rates into its taxonomy. This allowed AI-driven surfacing of “high-performing” assets. Campaign teams reported a 40% reduction in time spent selecting creative, and repurposed high-performing assets saw a 25% increase in ROI compared to new production.
Benchmark: Organizations linking asset metadata to performance data may increase marketing ROI by 15–25% due to better asset-to-channel matching.
4. Dynamic Governance
Taxonomy is being used as a compliance and governance mechanism — not just an organizational tool.
Example: A pharmaceutical company embedded regulatory compliance rules into taxonomy. Every asset in the DAM was tagged with approval stage, legal disclaimers, and expiration date. This reduced compliance violations by over 60%, avoiding potential fines estimated at $3M annually.
Benchmark: In regulated industries, marketing teams with compliance-driven taxonomy frameworks may experience 50–70% fewer regulatory interventions.
5. DAM Integration as the Backbone
Taxonomy works best when fully embedded within DAM systems, making them the single source of truth for global marketing.
Example: A multinational CPG company centralized taxonomy across 14 regional DAMs into a single enterprise DAM. This cut asset duplication by 35%, improved global-to-local creative reuse by 48%, and reduced annual creative production costs by $8M.
Benchmark: Enterprises with DAM-centered taxonomy can potentially save 20–40% on content production costs annually, primarily through reuse and faster localization.
Quantified Business Value of Leading Practices
When combined, these practices deliver measurable business outcomes:
30–40% reduction in duplicate creative costs (asset reuse).
20–30% faster campaign speed-to-market (taxonomy + DAM automation).
15–25% improvement in ROI (performance-linked metadata).
$5M–$10M annual savings for large global brands through unified taxonomy-driven DAM strategies.
Why Marketing Taxonomy is Critical for Operations
Efficiency: Reduced search and recreation time.
Cost Savings: 30–40% reduction in redundant asset production.
Speed-to-Market: Faster campaign launches.
Consistency: Standardized reporting across channels and geographies.
Future-Readiness: Foundation for automation, personalization, and AI.
In short: taxonomy is the nervous system of marketing operations. Without it, chaos prevails. With it, organizations achieve speed, control, and scale.
Part 2: The Role of Agentic AI in Marketing Taxonomy
Agentic AI introduces autonomous, adaptive intelligence into marketing operations. Where traditional taxonomy is static, agentic AI makes it dynamic, evolving, and self-optimizing.
Dynamic Categorization: AI agents automatically classify and reclassify assets in real time.
Adaptive Ontologies: Taxonomies evolve with new products, markets, and consumer behaviors.
Governance Enforcement: Agents flag off-brand or misclassified assets.
Performance-Driven Adjustments: Assets and campaigns are retagged based on outcome data.
In DAM, agentic AI automates ingestion, tagging, retrieval, lifecycle management, and optimization. In workflows, AI agents orchestrate campaigns internally—reducing reliance on agencies for execution.
1. From Static to Adaptive Taxonomies
Traditionally, taxonomies were predefined structures: hierarchical lists of categories, folders, or tags that rarely changed. The problem is that marketing is dynamic — new channels emerge, consumer behavior shifts, product lines expand. Static taxonomies cannot keep pace.
Agentic AI solves this by making taxonomy adaptive.
AI agents continuously ingest signals from campaigns, assets, and performance data.
When trends change (e.g., TikTok eclipses Facebook for a target persona), the taxonomy updates automatically to reflect the shift.
Instead of waiting for quarterly reviews or manual updates, taxonomy evolves in near real-time.
Example: A travel brand’s taxonomy originally grouped assets as “Summer | Winter | Spring | Fall.” After AI agents analyzed engagement data, they adapted the taxonomy to more customer-relevant categories: “Adventure | Relaxation | Family | Romantic.” Engagement lifted 22% in the first campaign using the AI-adapted taxonomy.
2. Intelligent Asset Tagging and Retrieval
One of the most visible roles of agentic AI is in automated asset classification. Legacy systems relied on humans manually applying metadata (“Product X, Q2, Paid Social”). This was slow, inconsistent, and error-prone.
Agentic AI agents change this:
Content-Aware Analysis: They “see” images, “read” copy, and “watch” videos to tag assets with descriptive, contextual, and even emotional metadata.
Performance-Enriched Tags: Tags evolve beyond static descriptors to include KPIs like CTR, conversion rate, or audience fit.
Semantic Search: Instead of searching “Q3 Product Launch Social Banner,” teams can query “best-performing creative for Gen Z on Instagram Stories,” and AI retrieves it instantly.
Example: A Fortune 500 retailer with over 1M assets in its DAM reduced search time by 60% after deploying agentic AI tagging, leading to a 35% improvement in asset reuse across global teams.
3. Governance, Compliance, and Brand Consistency
Taxonomy also plays a compliance and governance role. Misuse of logos, expired disclaimers, or regionally restricted assets can lead to costly mistakes.
Agentic AI strengthens governance:
Real-Time Brand Guardrails: Agents flag assets that violate brand rules (e.g., incorrect logo color or tone).
Regulatory Compliance: In industries like pharma or finance, agents prevent non-compliant assets from being deployed.
Lifecycle Enforcement: Assets approaching expiration are automatically quarantined or flagged for renewal.
Example: A pharmaceutical company using AI-driven compliance reduced regulatory interventions by 65%, saving over $2.5M annually in avoided fines.
4. Linking Taxonomy to Performance and Optimization
Legacy taxonomies answered the question: “What is this asset?” Agentic AI taxonomies answer the more valuable question: “How does this asset perform, and where should it be used next?”
Performance Attribution: Agents track which taxonomy categories drive engagement and conversions.
Dynamic Optimization: AI agents reclassify assets based on results (e.g., an email hero image with unexpectedly high CTR gets tagged for use in social campaigns).
Predictive Matching: AI predicts which asset-category combinations will perform best for upcoming campaigns.
Example: A beverage brand integrated performance data into taxonomy. AI agents identified that assets tagged “user-generated” had 42% higher engagement with Gen Z. Future campaigns prioritized this category, boosting ROI by 18% year-over-year.
5. Orchestration of Marketing Workflows
Taxonomy is not just about organization — it is the foundation for workflow orchestration.
Campaign Briefs: Agents generate briefs by pulling assets, performance history, and audience data tied to taxonomy categories.
Workflow Automation: Agents move assets through creation, approval, distribution, and archiving, with taxonomy as the organizing spine.
Cross-Platform Orchestration: Agents link DAM, CMS, CRM, and analytics tools using taxonomy to ensure all workflows remain aligned.
Example: A global CPG company used agentic AI to orchestrate regional campaign workflows. Campaign launch timelines dropped from 10 weeks to 6 weeks, saving 20,000 labor hours annually.
6. Strategic Impact of Agentic AI in Taxonomy
Agentic AI transforms marketing taxonomy into a strategic growth enabler:
Efficiency Gains: 30–40% reduction in redundant asset creation.
18–36 Months – Autonomy: Deploy predictive creative generation and dynamic budget optimization, supported by advanced governance.
Conclusion
Marketing taxonomy is not an administrative burden—it is the strategic backbone of marketing operations. When paired with agentic AI, it becomes a living, adaptive system that enables organizations to move away from costly, agency-controlled campaigns and toward internal, autonomous marketing ecosystems.
The result: faster time-to-market, reduced costs, improved governance, and a sustainable competitive advantage in digital marketing execution.