In the rapidly evolving business environment, leveraging the latest technology, especially AI and customer experience management (CEM), is often considered a primary component for achieving success. This is even more critical during economic recessions when businesses are faced with significant challenges. Understanding the implications of not employing these technologies during these periods is crucial in making informed strategic decisions.
The Losers: Ignoring Technology and Innovation
Companies that opt to ignore or underutilize technology such as AI and CEM during an economic recession are the likely losers in the long term. This is due to several reasons:
Decreased Operational Efficiency: AI can streamline operations and automate routine tasks, thereby reducing costs and improving efficiency. Businesses that do not leverage this during a recession may face higher operational costs and reduced profitability.
Inferior Customer Service: In the digital age, customers have come to expect personalized experiences, quick responses, and high-quality service. AI and CEM tools can help businesses deliver on these expectations. Without them, customer satisfaction may dwindle, leading to lost business.
Inability to Make Data-Driven Decisions: AI has revolutionized the way businesses analyze data and make decisions. It can provide predictive insights that can guide a business during challenging times. Companies not leveraging AI may lack these insights, leading to less effective decision-making.
The Winners: Embracing Technology as a Strategic Advantage
On the other hand, businesses that embrace AI and CEM are likely to emerge as winners during and after an economic recession. Here’s why:
Resilient Operations: By automating routine tasks and streamlining operations, businesses can reduce costs and maintain productivity even when resources are scarce.
Enhanced Customer Loyalty: Superior customer service fosters loyalty, which is crucial during a recession. When businesses are fighting for every customer, having a loyal customer base can make a significant difference.
Data-Driven Strategy: Businesses leveraging AI can make data-driven decisions that align with market trends and customer needs, allowing them to adapt to the changing economic landscape more effectively.
Balancing Technology Adoption and Business Strategy
However, it’s important to note that technology and business strategy are not in competition. Rather, they should be seen as complementary elements that, when integrated effectively, can help businesses navigate challenging economic conditions.
The most realistic approach to expanding your business during a recession involves a balanced strategy. Here are some steps to consider:
Embrace AI and CEM: Invest in these technologies to improve operational efficiency, enhance customer experiences, and make data-driven decisions.
Focus on Core Competencies: During a recession, it’s crucial to focus on what your business does best. Channel your resources towards areas where you can deliver the most value to your customers.
Maintain Financial Discipline: Keep a close eye on cash flows and maintain a tight rein on expenditures. Be strategic about where you invest and cut costs.
Pursue Strategic Partnerships: Forming partnerships can be a cost-effective way to expand your business and reach new customers.
Innovate: Recessions often present opportunities for innovation. Look for ways to meet the evolving needs of your customers and differentiate your business from competitors.
Conclusion
While economic recessions pose significant challenges, they also present opportunities for businesses to innovate, adapt, and strengthen their market position. By leveraging AI and CEM and aligning these technologies with a sound business strategy, businesses can not only survive an economic downturn but also set the stage for future growth.
Ultimately, the winners and losers of a recession are determined not by the circumstances, but by how businesses respond to these circumstances. Ignoring the latest technology is akin to refusing a lifeline in troubled waters. In contrast, those who adapt and leverage these tools are likely to navigate the storm successfully and emerge stronger on the other side.
In the long run, the most sustainable approach is to see technology not as a competitor but as a strategic partner that supports and enhances your business processes. During an economic recession, this approach can provide the resilience, agility, and competitive advantage necessary to not only survive but thrive amidst uncertainty.
So, take the time to understand and adopt these emerging technologies, align them with your business strategy, and prepare your business to weather any economic storm. After all, the goal is not just to survive the recession but to emerge from it stronger, more resilient, and ready for growth.
Artificial intelligence (AI) has been advancing at a rapid pace over the past few years, making strides in everything from natural language processing to computer vision. Two of the most influential architectures driving these advancements are transformer:
A transformer diffusion model is a deep learning model that uses transformers to learn the latent structure of a dataset. Transformers are distinguished by their use of self-attention, which differentially weights the significance of each part of the input data. In image generation tasks, the prior is often either a text, an image, or a semantic map. A transformer is used to embed the text or image into a latent vector. The released Stable Diffusion model uses ClipText (A GPT-based model), while the paper used BERT. Diffusion models have achieved amazing results in image generation over the past year. Almost all of these models use a convolutional U-Net as a backbone.
and latent diffusion models:
A latent diffusion model (LDM) is a type of machine learning model that can generate detailed images from text descriptions. LDMs use an auto-encoder to map between image space and latent space. The diffusion model works on the latent space, which makes it easier to train. LDMs enable high-quality image synthesis while avoiding excessive compute demands by training a diffusion model in a compressed lower-dimensional latent space. Stable Diffusion is a latent diffusion model.
As we delve deeper into the world of AI, it’s crucial to understand these models and the critical roles they play in this exciting AI wave.
Understanding Transformers and Latent Diffusion Models
Transformers
The transformer model, introduced in a paper titled “Attention is All You Need” by Vaswani et al., in 2017, revolutionized the field of natural language processing (NLP). The model uses a mechanism known as “attention” to weight the influence of different words when generating an output. This allows the model to consider the context of each word in a sentence, enabling it to generate more nuanced and accurate translations, summaries, and other language tasks.
A key advantage of transformers over previous models, such as recurrent neural networks (RNNs), is their ability to handle “long-range dependencies.” In natural language, the meaning of a word can depend on words much earlier in the sentence. For instance, in the sentence “The cat, which we found last week, is very friendly,” the subject “cat” is far from the verb “is.” Transformers can handle these types of sentences more effectively than RNNs.
Latent Diffusion Models
In contrast to transformer models, which have largely revolutionized NLP, latent diffusion models are an exciting development in the world of generative models. Introduced by Sohl-Dickstein et al., in 2015, they are designed to model the distribution of data, allowing them to generate new, original content.
Latent diffusion models work by simulating a random process in which an initial point (representing a data point) undergoes a series of small random changes, or “diffusions,” gradually transforming into a different point. By learning to reverse this process, the model can start from a simple random point and gradually “diffuse” it into a new, original data point that looks like it could have come from the training data.
These models have seen impressive results in areas like image and audio generation. They’ve been used to create everything from realistic human faces to original music.
The Role of Transformer and Latent Diffusion Models in the Current AI Wave
Transformer and latent diffusion models are fueling the current AI wave in several ways.
Expanding AI Capabilities
Transformers, primarily through models like OpenAI’s GPT-3, have dramatically expanded the capabilities of AI in understanding and generating natural language. They have enabled the development of more sophisticated chatbots, more accurate translation systems, and tools that can generate human-like text, such as articles and stories.
Meanwhile, latent diffusion models have shown impressive results in generating realistic images, music, and other types of content. For instance, DALL-E, a variant of GPT-3 trained to generate images from textual descriptions, leverages a similar concept.
Democratizing AI
These models have also played a significant role in democratizing access to AI technology. Pre-trained models are widely available and can be fine-tuned for specific tasks with smaller amounts of data, making them accessible to small and medium-sized businesses that may not have the resources to train large models from scratch.
Deploying Transformers and Latent Diffusion Models in Small to Medium Size Businesses
For small to medium-sized businesses, deploying AI models might seem like a daunting task. However, with the current resources and tools, it’s more accessible than ever.
Leveraging Pre-trained Models
One of the most effective ways for businesses to leverage these models is by using pre-trained models (examples below). These are models that have already been trained on large datasets and can be fine-tuned for specific tasks. Both transformer and latent diffusion models can be fine-tuned this way. For instance, a company might use a pre-trained transformer model for tasks like customer service chatbots, sentiment analysis, or document summarization.
Pre-trained models are AI models that have been trained on a large dataset and are made available for others to use, either directly or as a starting point for further training. They’re a crucial resource in machine learning, as they can save significant time and computational resources, and they can often achieve better performance than models trained from scratch, particularly for those who may not have access to large-scale data. Here are some examples of pre-trained models in AI:
BERT(Bidirectional Encoder Representations from Transformers): This is a transformer-based machine learning technique for natural language processing tasks. BERT is designed to understand the context of each side of a word (left and right sides). It’s used for tasks like question answering and language inference.
GPT-3(Generative Pre-trained Transformer 3): This is a state-of-the-art autoregressive language model that uses deep learning to produce human-like text. It’s the latest version of the GPT series by OpenAI.
RoBERTa(A Robustly Optimized BERT Pre-training Approach): This model is a variant of BERT that uses different training strategies and larger batch sizes to achieve even better performance.
ResNet (Residual Networks): This is a type of convolutional neural network (CNN) that’s widely used in computer vision tasks. ResNet models use “skip connections” to avoid problems with training deep networks.
Inception(e.g., Inception-v3): This is another type of CNN used for image recognition. Inception networks use a complex, multi-path architecture to allow for more efficient learning.
MobileNet: This is a type of CNN designed to be efficient enough for use on mobile devices. It uses depthwise separable convolutions to reduce computational requirements.
T5 (Text-to-Text Transfer Transformer): This model by Google treats every NLP problem as a text-to-text problem, allowing it to handle tasks like translation, summarization, and question answering with a single model.
StyleGAN and StyleGAN2: These are generative adversarial networks (GANs) developed by NVIDIA that are capable of generating high-quality, photorealistic images.
VGG (Visual Geometry Group): This is a type of CNN known for its simplicity and effectiveness in image classification tasks.
YOLO (You Only Look Once): This model is used for object detection in images. It’s known for being able to detect objects in images with a single pass through the network, making it very fast compared to other object detection methods.
These pre-trained models are commonly used as a starting point for training a model on a specific task. They have been trained on large, general datasets and have learned to extract useful features from the input data, which can often be applied to a wide range of tasks.
Utilizing Cloud Services
Various cloud services offer AI capabilities that utilize transformer and latent diffusion models. These services provide an easy-to-use interface and handle much of the complexity behind the scenes, enabling businesses without extensive AI expertise to benefit from these models.
How These Models Compare to Large Language Models
Large language models like GPT-3 are a type of transformer model. They’re trained on vast amounts of text data and have the ability to generate human-like text that is contextually relevant and sophisticated. In essence, these models are a testament to the power and potential of transformers.
Latent diffusion models, on the other hand, work in a fundamentally different way. They are generative models designed to create new, original data that resembles the training data. While large language models are primarily used for tasks involving text, latent diffusion models are often used for generating other types of data, such as images or music.
The Future of Transformer and Latent Diffusion Models
Looking towards the future, it’s clear that transformer and latent diffusion models will continue to play a significant role in AI.
Near-Term Vision
In the near term, we can expect to see continued improvements in these models’ performance, as well as their deployment in a wider range of applications. For instance, transformer models are already being used to improve search engine algorithms, and latent diffusion models could be used to generate personalized content for users.
Long-Term Vision
In the longer term, the possibilities are even more exciting. Transformer models could enable truly conversational AI, capable of understanding and responding to human language with a level of nuance and sophistication that rivals human conversation. Latent diffusion models, meanwhile, could enable the creation of entirely new types of media, from AI-generated music to virtual reality environments that can be generated on the fly.
Moreover, as AI becomes more integrated into our lives and businesses, it’s crucial that these models are developed and used responsibly, with careful consideration of their ethical implications.
Conclusion
Transformer and latent diffusion models are fueling the current wave of AI innovation, enabling new capabilities and democratizing access to AI technology. As we look to the future, these models promise to drive even more exciting advancements, transforming the way we interact with technology and the world around us. It’s an exciting time to be involved in the field of AI, and the potential of these models is just beginning to be tapped.
In the rapidly evolving digital age, emerging technologies such as Artificial Intelligence (AI), Customer Experience Management (CEM), Digital Marketing, and Master Data Management (MDM) are transforming the way brands operate and how customers interact with them. Today’s blog post delves into these disruptive technologies, exploring how they’re reshaping our daily lives and revolutionizing the business landscape.
Artificial Intelligence: The Smart Solution
Artificial Intelligence (AI) is no longer a distant reality or science fiction fantasy—it’s here and revolutionizing businesses, irrespective of their sizes or industries. AI systems have the ability to learn, reason, and even self-correct. This gives them the power to provide a level of service and efficiency that humans can’t match, augmenting our capabilities and complementing our efforts.
AI’s impact on the business sector is profound, reshaping everything from customer service to marketing strategy. For example, chatbots are streamlining customer service by responding to queries instantly and at any hour of the day. However, a company must not default solely to chatbots, escalated customer issues and overuse can easily alienate your most loyal customers. In marketing, AI algorithms analyze customer behavior to deliver highly personalized ad campaigns, which leads to improved customer engagement and higher conversion rates.
But AI’s potential goes far beyond customer interactions. Behind the scenes, it’s optimizing business processes, automating repetitive tasks, enhancing security, and delivering valuable insights through advanced analytics. This allows companies to be more efficient, innovative, and responsive to customer needs.
In an age where customer loyalty is largely determined by experience rather than price or product, Customer Experience Management (CEM) is becoming increasingly crucial. This strategic approach involves understanding customer needs, designing the optimal customer journey, and consistently delivering a high-quality, personalized experience.
CEM is being supercharged by the latest technologies. AI, for example, helps businesses anticipate customer needs and preferences, allowing them to deliver hyper-personalized experiences. Advanced analytics tools, on the other hand, provide insights into customer behavior, enabling brands to continually improve their offerings and interactions.
One significant advantage of an effective CEM strategy is the ability to turn customers into brand advocates. Satisfied customers don’t just make repeat purchases; they also become a powerful marketing tool, promoting the brand to their friends, family, and social media followers.
Digital Marketing: Engaging Customers in the Digital Age
In today’s digital era, marketing has evolved beyond billboards, television ads, and radio spots. Brands are harnessing the power of the internet and technology to reach consumers, utilizing strategies that engage customers and personalize messages like never before.
Digital marketing uses various channels—including search engines, social media, email, and websites—to connect with current and prospective customers. AI and big data analytics have transformed this sector, enabling companies to analyze vast amounts of data to understand customer behavior, preferences, and needs. This allows for highly targeted marketing campaigns that are more effective and efficient.
Furthermore, advanced technologies are providing new opportunities for interactive and immersive marketing. Augmented reality (AR), virtual reality (VR), and interactive video content, for instance, offer unique, engaging experiences that can captivate customers and significantly enhance brand perception.
Master Data Management: Driving Consistency and Efficiency
Master Data Management (MDM) is a comprehensive method of enabling an organization to link all of its critical data to one file, known as a master file, which provides a common point of reference. It ensures data accuracy, uniformity, and consistency across the entire organization.
With the explosion of data in recent years, MDM has become an essential tool for businesses. It enables companies to make better decisions by providing accurate, up-to-date, and holistic data. Moreover, it promotes efficiency by preventing data duplication and inconsistency.
AI and machine learning are further enhancing MDM, automating data cleansing, integration, and management, thus improving data quality while reducing manual efforts and errors. AI can also detect patterns and provide insights that would otherwise be difficult to discover, thereby enabling businesses to make more informed decisions and strategic plans.
MDM, when combined with other technologies like AI and advanced analytics, forms a powerful foundation for various initiatives, including personalization, predictive analytics, and customer experience management. This holistic approach allows brands to provide consistent, personalized, and relevant experiences across all touchpoints, which significantly improves customer satisfaction and loyalty.
The Intersection of Technologies: A Unified Digital Transformation Strategy
While each of these technologies—AI, CEM, Digital Marketing, and MDM—can individually drive significant changes in business operations and customer experiences, their real power lies in their convergence. The intersection of these technologies allows brands to implement a unified digital transformation strategy that revolutionizes every aspect of their operations.
For instance, AI-powered chatbots (AI) can provide personalized customer service (CEM) based on insights gained from a unified view of customer data (MDM), while also providing a unique touchpoint for digital marketing campaigns. This cohesive, integrated approach enables companies to be more agile, innovative, customer-centric, and competitive in today’s digital age.
The Future: Adapting to an Ever-Evolving Digital Landscape
The technological landscape is evolving at a rapid pace, with advancements in AI, CEM, Digital Marketing, and MDM reshaping the way brands operate and engage with their customers. These technologies are not just transforming businesses—they’re also altering customers’ expectations and behaviors.
As a result, companies must be agile, willing to adapt and innovate continuously to stay ahead of the curve. This involves not just implementing these technologies but also cultivating a culture of digital transformation, one that embraces change, fosters innovation, and prioritizes customer needs.
Conclusion: Embrace the Digital Revolution
In conclusion, the digital revolution, driven by AI, CEM, Digital Marketing, and MDM, is fundamentally changing how brands and customers interact. For brands, these technologies offer opportunities for improved efficiency, innovation, and customer engagement. For customers, they promise more personalized, convenient, and engaging experiences.
Embracing these technologies is not an option—it’s a necessity for brands that want to thrive in this digital age. By leveraging AI, CEM, Digital Marketing, and MDM, brands can transform their operations, exceed customer expectations, and gain a competitive edge. It’s an exciting time to be a part of this digital revolution, and the possibilities for the future are limitless.
Advancements in artificial intelligence (AI) have brought about a paradigm shift, particularly in the realm of machine learning. As these technologies evolve, there is an increasing emphasis on multi-modal learning. Multi-modal learning revolves around the idea of integrating information from different sources or ‘modalities’ to enhance the learning process. This can include visual data, audio data, text, and even haptic feedback, among others. In this post, we delve deep into the concept of fusion strategies, which is the heart of multi-modal learning, and how AI systems should combine these different modalities for effective learning outcomes.
What is Fusion?
To fully appreciate the power of multi-modal learning, we first need to understand what ‘fusion’ means in this context. Fusion, in the realm of AI and machine learning, refers to the process of integrating various data modalities to produce more nuanced and reliable results than would be possible using a single modality.
Imagine a scenario where an AI system is trained to transcribe a conversation. If the system has only audio data to rely upon, it may struggle with accents, ambient noise, or overlapping speech. However, if the AI can also access video data—lip movements, facial expressions—it can leverage this additional modality to improve transcription accuracy. This is an example of fusion in action.
Types of Fusion Strategies
Fusion strategies can be broadly classified into three categories: Early Fusion, Late Fusion, and Hybrid Fusion.
1. Early Fusion: Early fusion, also known as feature-level fusion, involves combining different modalities at the input level before they are processed by the model. The integrated data is then fed into the model for processing. This approach can capture the correlations between different modalities at the cost of being computationally expensive and requiring all modalities to be available at the time of input.
2. Late Fusion: Late fusion, also known as decision-level fusion, involves processing each modality separately through different models and combining the outputs at the end. This allows the model to make decisions based on the individual strengths of each modality. It is less computationally intensive than early fusion and can handle modalities being available at different times. However, it may not capture the correlations between modalities as effectively as early fusion.
3. Hybrid Fusion: As the name suggests, hybrid fusion is a blend of early and late fusion strategies. It aims to leverage the strengths of both approaches, capturing correlations between modalities while also being flexible and less demanding computationally. Hybrid fusion strategies usually involve performing early fusion on some modalities and late fusion on others, or applying early fusion and then adding additional modalities via late fusion.
How Should an AI System Combine Information from Different Modalities?
Choosing the right fusion strategy depends on the nature of the task, the modalities involved, and the specific requirements of the system.
1. Consider the Nature of the Task: Tasks that require an understanding of the correlation between modalities may benefit from early fusion. For example, in video captioning, the visual and audio components are closely related, and combining these modalities early in the process can enhance the model’s performance.
2. Evaluate the Modalities: The characteristics of the modalities also influence the choice of fusion strategy. For instance, when dealing with high-dimensional data like images and video, early fusion might be computationally prohibitive. In such cases, late fusion might be a more feasible approach.
3. Assess System Requirements: If real-time processing and flexibility with asynchronous modalities are crucial, late fusion or hybrid fusion might be the preferred choice.
There isn’t a one-size-fits-all solution when it comes to fusion strategies in multi-modal learning. The key lies in understanding the technicalities of the task at hand, the modalities in play, and the specific requirements of the system, and then selecting the fusion strategy that best aligns with these factors.
Recent Advances in Fusion Strategies
Despite the challenges, researchers are pushing the boundaries and continually developing innovative fusion strategies for multi-modal learning. Several promising directions in this field include:
1. Cross-modal Attention Mechanisms: Attention mechanisms have been a popular technique in machine learning, initially proving their worth in Natural Language Processing (NLP) tasks. They have now made their way into the realm of multi-modal learning, with cross-modal attention mechanisms proving particularly promising. These models can learn to “pay attention” to relevant features across different modalities, leading to more effective fusion and ultimately better performance.
2. Graph-based Fusion: Graph-based methods are another area of interest. Here, different modalities are represented as nodes in a graph, with the edges denoting interactions between these modalities. The graph structure allows for a rich representation of the relationships between modalities, and it can be a powerful tool for fusion.
3. Deep Fusion Techniques: With the advent of deep learning, more complex fusion techniques have become feasible. For instance, multi-layer fusion strategies can execute fusion at different levels of abstraction, enabling the model to capture both low-level and high-level interactions between modalities.
The Role of Context in Fusion Strategies
The decision of which fusion strategy to adopt is not solely determined by the nature of the task or the characteristics of the modalities. The context in which the AI system operates also plays a significant role. For instance, if an AI system is designed to operate in an environment where network latency is high or where computing resources are limited, a late fusion strategy could be more appropriate due to its lower computational requirements.
Similarly, if the system is deployed in a setting where certain modalities might be unavailable or unreliable—such as in a noisy environment where audio data might be compromised—a late or hybrid fusion strategy could be more suitable as they offer greater flexibility in dealing with missing or uncertain data.
The Importance of Evaluation Metrics
The choice of fusion strategy should also be informed by the evaluation metrics that are important for the task at hand. Different fusion strategies might optimize for different aspects of performance. For example, an early fusion strategy might lead to higher accuracy by capturing intricate correlations between modalities, while a late fusion strategy might offer faster processing times or better handling of missing or asynchronous data.
Hence, it’s important to clearly define the success metrics for your AI system—be it accuracy, speed, robustness, or some other criterion—and to choose a fusion strategy that aligns with these objectives.
The Future of Fusion Strategies
Given the rapid progress in AI and machine learning, it’s clear that the future holds exciting possibilities for fusion strategies in multi-modal learning.
With advancements in technologies like 5G and the Internet of Things (IoT), we can expect an explosion in the availability of diverse and rich data from multiple modalities. This will provide unprecedented opportunities for multi-modal learning, and the demand for effective and efficient fusion strategies will only grow.
In the future, we can anticipate more sophisticated fusion strategies that leverage the power of deep learning and other advanced techniques to capture complex correlations between modalities and deliver superior performance. For instance, we could see fusion strategies that dynamically adapt to the context, selecting different approaches for different tasks or environments. Or we could see strategies that incorporate elements of reinforcement learning, allowing the AI system to learn and improve its fusion strategy over time based on feedback.
At the same time, we must also be mindful of the challenges that lie ahead. As we deal with more and complex data from diverse modalities, issues like data privacy, algorithmic fairness, and interpretability will become increasingly important. As such, the development of fusion strategies will need to be guided not only by considerations of performance and efficiency but also by ethical and societal considerations.
Conclusion Fusion strategies are at the heart of multi-modal learning, and they hold the key to unlocking the full potential of AI systems. By carefully considering the task, the modalities, the context, and the desired outcomes, we can select the most effective fusion strategy and build AI systems that are truly greater than the sum of their parts. As we look to the future, the possibilities for fusion strategies in multi-modal learning are exciting and virtually limitless. The journey has only just begun, and the destination promises to be nothing short of revolutionary.
Today we introduce a new addition to our blog posts – The AI Weekend’s section, where we dive more in-depth about the latest trends in AI and add a little education / execution / practicality, and even perhaps providing you with a vision in ultimately making you more confident when applying AI to your CRM / CX / CEM strategy. We start this series a bit heavy (Cross-Modal Generative AI), but we believe it’s better to understand from the broad definition and work our way to the granular.
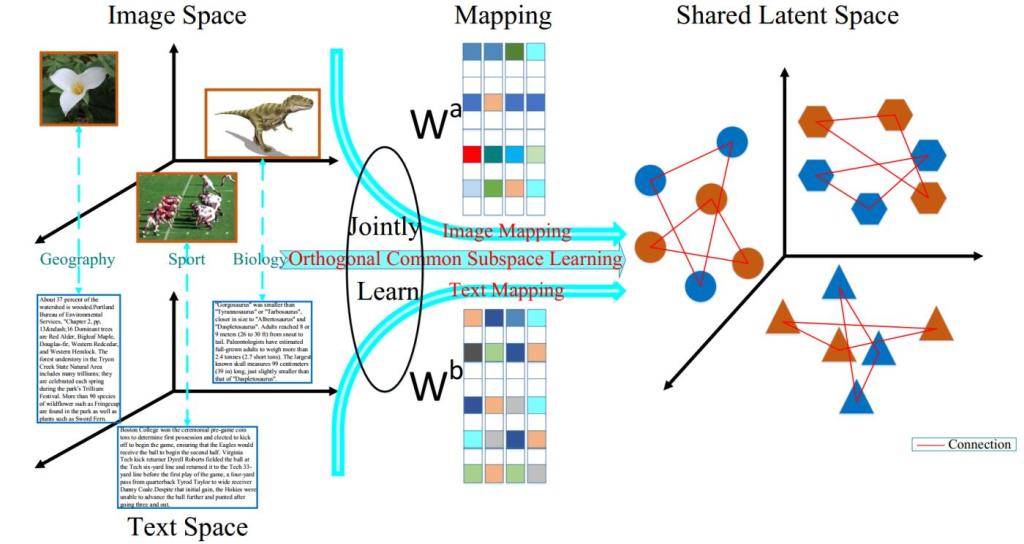
Artificial intelligence (AI) has made staggering leaps in recent years. One such innovative leap is in the field of cross-modal learning, which refers to the ability of AI models to leverage data from various modalities (or forms), such as text, images, videos, and sounds, to develop a comprehensive understanding and make intelligent decisions.
Most notably, this technology is being used in generative AI – systems designed to create new content that’s similar to the data they’ve been trained on. By combining cross-modal learning with generative models, AI can not only understand multiple types of data but also generate new, creative content across different modalities. This advancement propels AI’s creative capacity to new heights, taking us beyond the era of unimodal generative models such as GPT-4, DALL-E, and others.
But what is cross-modal learning:
Cross-modal generative AI represents the cutting edge of artificial intelligence technology. To truly understand its underlying technology, we first need to examine its two key components: cross-modal learning and generative AI.
Cross-Modal Learning: At its core, cross-modal learning refers to the process of leveraging and integrating information from different forms of data, or ‘modalities.’ This can include text, images, audio, video, and more. In the context of AI, this is typically achieved using machine learning algorithms that can ‘learn’ to identify and understand patterns across these different data types.
A critical aspect of this is the use of representation learning, where the AI is trained to convert raw data into a form that’s easier for machine learning algorithms to understand. For example, it might convert images into a series of numerical vectors that represent different features of the image, like color, shape, and texture.
Cross-modal learning also often involves techniques like transfer learning (where knowledge gained from one task is applied to another, related task) and multi-task learning (where the AI is trained on multiple tasks at once, encouraging it to develop a more generalized understanding of the data).
Generative AI: Generative AI refers to systems that can create new content that’s similar to the data they’ve been trained on. One of the most common techniques used for this is Generative Adversarial Networks (GANs).
GANs involve two neural networks: a generator and a discriminator. The generator creates new content, while the discriminator evaluates this content against the real data. The generator gradually improves its output in an attempt to ‘fool’ the discriminator. Other methods include Variational Autoencoders (VAEs) and autoregressive models like the Transformer, which was used to create models like GPT-4.
Cross-modal generative AI brings these two components together, allowing AI to understand, interpret, and generate new content across different forms of data. This involves training the AI on massive datasets containing various types of data, and using advanced algorithms that can handle the complexities of multimodal data.
For instance, the AI might be trained using a dataset that contains pairs of images and descriptions. By learning the relationships between these images and their corresponding text, the AI can then generate a description for a new image it’s never seen before, or create an image based on a given description.
In essence, the technology behind cross-modal generative AI is a blend of advanced machine learning techniques that allow it to understand and generate a wide range of data types. As this technology continues to evolve, it’s likely we’ll see even more innovative uses of this capability, further blurring the lines between different forms of data and creating even more powerful and versatile AI systems.
Cross-Modal Generative AI in the Customer Experience Space
The exciting implications of cross-modal generative AI are particularly potent in the context of customer experience. As businesses become more digital and interconnected, customer experience has grown to encompass multiple modalities. Today’s customers interact with brands through text, voice, video, and other interactive content across multiple channels. Here are some practical applications of this technology:
1. Personalized Advertising: Cross-modal generative AI can take user preferences and behaviors across different channels and generate personalized advertisements. For instance, it could analyze a customer’s text interactions with a brand, the videos they watched, the images they liked, and then create tailored advertisements that would resonate with that customer.
2. Multimodal Customer Support: Traditional AI customer support often falls short in handling complex queries. By understanding and integrating information from text, audio, and even video inputs, cross-modal AI can provide a much more nuanced and effective customer support. It could generate responses not just in text, but also in the form of images, videos, or audio messages if needed.
3. Improved Accessibility: Cross-modal generative AI can make digital spaces more accessible. For example, it could generate descriptive text for images or videos for visually impaired users, or create sign language videos to describe textual content for hearing-impaired users.
4. Enhanced User Engagement: AI can generate cross-modal content, such as text-based games that produce sounds and images based on user inputs, creating a rich, immersive experience. This can help businesses differentiate themselves and improve user engagement.
Measuring the Success of Cross-Modal Generative AI Deployment
As with any technology deployment, measuring the success of cross-modal generative AI requires defining key performance indicators (KPIs). Here are some factors to consider:
1. Customer Satisfaction: Surveys can be used to understand whether the deployment of this AI technology has led to an improved customer experience.
2. Engagement Metrics: Increased interaction with AI-generated content or enhanced user activity could be an indicator of success. This can be measured through click-through rates, time spent on a page, or interactions per visit.
3. Conversion Rates: The ultimate goal of improved customer experience is to drive business results. A successful deployment should see an increase in conversion rates, be it sales, sign-ups, or any other business-specific action.
4. Accessibility Metrics: If one of your goals is improved accessibility, you can measure the increase in the number of users who take advantage of these features.
5. Cost Efficiency: Measure the reduction in customer service costs or the efficiency gained in advertising spend due to the personalized nature of the ads generated by the AI.
The Future of Cross-Modal Generative AI
The integration of cross-modal learning and generative AI presents a transformative opportunity. Its capabilities are expanding beyond mere novelty to becoming a crucial component of a robust customer experience strategy. However, as with any pioneering technology, the full potential of cross-modal generative AI is yet to be realized.
Looking ahead, we can envision several avenues for future development:
1. Interactive Virtual Reality (VR) and Augmented Reality (AR) Experiences: With the ability to understand and generate content across different modalities, AI could play a significant role in crafting immersive VR and AR experiences. This could transform sectors like retail, real estate, and entertainment, creating truly interactive and personalized experiences for customers.
2. Advanced Content Creation and Curation: Cross-modal generative AI could revolutionize content creation and curation by auto-generating blog posts with suitable images, videos, and audio, creating engaging and varied content tailored to the preferences of the individual consumer.
3. Intelligent Digital Assistants: The future of digital assistants lies in their ability to interact more naturally, understanding commands and providing responses across multiple modes of communication. By leveraging cross-modal learning, the next generation of digital assistants could respond to queries with text, visuals, or even synthesized speech, creating a more human-like interaction.
Conclusion
In the rapidly evolving landscape of artificial intelligence, cross-modal generative AI stands out as a particularly promising development. Its ability to integrate multiple forms of data and output offers rich possibilities for improving the customer experience, adding a new layer of personalization, interactivity, and creativity to digital interactions.
However, as businesses begin to adopt and integrate this technology into their operations, it’s crucial to approach it strategically, defining clear objectives and KPIs, and constantly measuring and refining its performance.
While there will certainly be challenges and learning curves ahead, the potential benefits of cross-modal generative AI make it an exciting frontier for businesses looking to elevate their customer experience and stay ahead in the digital age. With continued advancements and thoughtful application, this technology has the potential to reshape our understanding of AI’s role in customer experience, moving us closer to a future where AI can truly understand and interact with humans in a multimodal and multidimensional way.